We are excited to announce that we are working with KiwiSDR to bring Software Defined Radio to the BeagleBone.
WHAT IS KIWISDR?
KiwiSDR is a software-defined radio (SDR) covering shortwave, the longwave & AM broadcast bands, various utility stations, and amateur radio transmissions, world-wide, in the spectrum from 10 kHz to 30 MHz. The KiwiSDR is a custom circuit board (cape) you attach to a BeagleBone Black or Green. Add an antenna, power supply, internet connection, then install the software package and be running in minutes.
An HTML5-capable browser and internet connection will let you listen to a public KiwiSDR anywhere in the world. Up to four people can listen simultaneously to one receiver -- each listener tunes independently.
Kickstarter
The KiwiSDR project has launched on kickstarter. Please help us make this happen by backing us!
More information
For more details about the KiwiSDR see the KiwiSDR product page or visit the kickstarter page.
We are excited to announce that the LOGI boards are back in stock at element14. We hope you like the changes made on the new boards. The latest boards are being call Version 2 at element14, with the revision number being R1.5. We hope to keep cranking out the boards and have some designs in the pipeline, which we are figuring out when and how we will be releasing these. Stay tuned!
Note that the LOGI-Cam was not MFG'd and will not be carried by element14. This is based upon the OEM OV7670 module not passing FCC/CE testing, which is outside of our control. We are in the process of designing a new camera module, which will support many new features including Parallel orLVDS interfacing, Snapshot feature, stereo vision operations. We will keep you posted on this progress and hope to have something in your hands soon. In the mean time, we do have extra stock of the old LOGI-Cam which we can sell directly - email support@valentfx.com if interested.
You can find the LOGI boards at www.element14.com/logi
Here are the change listings for the LOGI boards.
LOGI Pi Version 2 Change Listing
FCC and CE Compliance
The LOGI Pi design has undergone testing to meet FCC and CE certifications.
GPIO Expander
An I2C GPIO expander was added to handle FPGA IO control during programming. This Frees up Raspberry Pi GPIO pins for other uses.
Mounting Holes
Mounting holes to support the Raspberry Pi B+/2 were added. This give support for all Raspberry Pi Board variants including A/B/B+/2.
Micro-USB connector for Power
A Micro-USB connector was added to allow additional power to be supplied to the LOGI board in the case of high powered applications or for use as a standalone board.
Increased Flash size from 16Mbit to 32Mbit
A new SPI flash was used which increases the memory from 16Mbit to a 32Mbit.
SPI Buffer to FPGA and Flash
An IO buffer was added on the Raspberry Pi SPI pins that allow the SPI port to be isolated from the Flash chip pins when not being used for FPGA configuration. The Flash chip can then be directly accessed from the FPGA without conflicting with communication between the Rasperry Pi and the FPGA.
LOGI Bone Version 2 Change Listing
FCC and CE Compliance
The LOGI Bone design has undergone testing to meet FCC and CE certifications.
GPIO Expander
An smaller I2C GPIO expander was added to handle FPGA IO control during programming.
Micro-USB connector for Power
A Micro-USB connector was added to allow additional power to be supplied to the LOGI board in the case of high powered applications or for use as a standalone board.
Increased Flash size from 16Mbit to 32Mbit
A new SPI flash was used which increases the memory from 16Mbit to a 32Mbit.
SPI Buffer to FPGA and Flash
An IO buffer was added on the BeagleBone SPI pins that allow the SPI port to be isolated from the Flash chip pins when not being used for FPGA configuration. The Flash chip can then be directly accessed from the FPGA without conflicting with communication between the BeagleBone and the FPGA.
LOGI EDU Version 2 Change Listing
LOGI Bone and LOGI Pi compatible
The LOGI EDU can now be used with the LOGI Bone by using 2 PMOD ports of the LOGI EDU at a time. The LOGI EDU pins were optimized to partition onboard functionality between two sets of PMOD ports. The user can select which functionality they would like to use connect to the appropriate set of EDU PMOD ports to access the functionality.

FPGA Camera Data Processing
This is part 1 of a 2 part article which details interfacing a camera to an FPGA, capturing the data and then processing the data using a pipelining technique. One of the many strengths of using an FPGA is the speed and flexibility it gives to processing data in a real-time manner. An interface to a camera is a good example of this case scenario where cameras output very high amounts of data very quickly and generally customized or dedicated hardware is required to process this data.
One specific attribute of an FPGA is that it can be used to implement a given processing task directly at the data-source, in this case: the camera. This means that with a good understanding of the signals generated by the camera we can adapt image filters to directly process the signals generated by the camera instead of processing an image stored in memory like a CPU would do, i.e. real-time processing.
A camera is a pixel streaming device. It converts the photon into binary information for each pixel. Each pixel is a photon integrator that generates an analog signal followed by an analog to digital converter. The camera then transmits on it’s databus the captured information, one pixel at a time, one row after the other. The pixel can be captured in two different ways that directly affect the kind of application the sensor can be used in, including rolling shutter and global shutter sensors.
Rolling Shutter Camera Sensors
Rolling-shutter sensors are widely adopted because they are cheap and can be built for high resolution images. These sensors do not acquire all the pixels at once, but one line after the other. Because all the pixels are not exposed at the same time, it generates artifacts in the image. For examples take a picture of a rotating fan and observe the shape of the fan blades (see image below for comparison). Another noticeable effect can be seen when taking a picture of scene with a halogen or fluorescent light. When using a halogen or fluorescent light all the pixel lines are not exposed with the same amount of light because light intensity varies at 50/60Hz, which is driven by the mains frequency.
Global Shutter Camera Sensors
Global shutter sensor are more expensive and are often used in machine vision. For these sensors all of the pixels are exposed at the same time with a snapshot. The pixels informations is then streamed to the capturing device (FPGA in our case). These sensors are more expensive because they require more dedicated logic to record all the pixels at once (buffering). Moreover, the sensor die is larger (larger silicon surface), because the same surface contains the photon integrators and the buffering logic.

Once captured, the pixel data can be streamed over different interfaces to the host device (FPGA in our case). Examples of typical camera data interfaces are parallel interfaces or CSI/LVDS serial interfaces. The parallel interface is composed of a set of electrical signals (one signal per data bit), and is limited in the distance the data can be transmitted (inches in scale). The serial interface sends the different pixel information one after another using the same data lines, positive and negative differential pair. LVDS (Low Voltage Differential Signaling) carries the serial data at high rates (up to 500Mbps for a camera) and allows transmission for longer distances (up to 3 feet on the LOGI SATA type connector).
The LOGI Cam
The LOGI Cam supports many of the Omnivision camera modules, but is shipped with the OV7670 which is a low cost rolling shutter sensor that exposes a parallel data bus with the following signals.
pclk: the synchronization clock to sample every other signal, this signal is active all the time
href: href indicates that a line is being transmitted
vsync: vsync indicate the start of a new image
pixel_data: the 8-bit data-bus that carry pixel information at each pclk pulse when href is active
sio_c/sio_d: an i2c like interface to configure the sensor

Fig 0: First diagram show how pixel are transmitted in a line. Second part is a zoom out of the transmission, and just show how line are transmitted in an image.
Pixel Data Coded Representations
The parallel data bus is common for low cost sensors and is well suited to stream pixel data. What one will notice is that the pixel data is only 8 bits wide, which leads to the question, how does the camera send a color data without more that 8 bits per pixel on this data bus? The answer is that each component of the pixel is sent one after another in sequence until the complete pixel data has been transmitted. This means that for a QVGA (240 lines of 320 pixels per line) color image, with 2 bytes per pixel, the camera sends 240 lines of 640 values (2 bytes per pixel).
RGB Color Space
One might wonder how the camera can compose each pixel’s color data with only 2 bytes (i.e. does it produce only 2^16 or 65536 different values)? There are two typical ways to represent the pixel colors, RGB (Red Green Blue) and YUV coding. RGB coding will split the 16bits (two bytes) into an RGB value, on the camera this is called RGB 565, which means that 16bits are split into 5 bits for red, 6 bits for green, 5 bits for blue. You will note that there is an extra bit for the green data. This interesting point is guided by our animal nature which programs our eyes to be more sensitive to subtle changes in green, therefore to create the best range of for a color requires us to add an extra green data bit *. With RGB565 there is a total of 65536 colors based upon a total of 16 color bits available per pixel.
YUV Color Space
The second way of coding pixel data is called YUV (or YCrCb), Y stands for luminance (the intensity of light for each pixel), U/Cr is the red component of the image and V/Cb is the blue component of the image. In YUV, instead of down-scaling the number of bits for each YUV component, the approach is to downscale the resolution for the U/V values. Our eyes are more sensitive to luminance than to color due to the fact that the eye has more rod cells responsible for sensing luminance than cone cells that can sense the colors*. There are a number of YUV formats including YUV 4:4:4, YUV 4:2:2, YUV 4:2:0. Each format will produce a full resolution image for the Y component (each pixel has a Y value) and a downscaled resolution for U/V. In the camera the Y component resolution has at native resolution of 320x240 for QVGA and U/V resolution is down-scaled for each line (160x240 for QVGA), that is the YUV 4:2:2 format. See Figure 1 for a depiction of how the image is broken into components of full resolution Y and downscaled resolution of U/V components. Note that all of the bits are being used for each YUV component, but only every other U/V component is used to downscale the total image size.
* For more information on this topic see the links at the end of the page
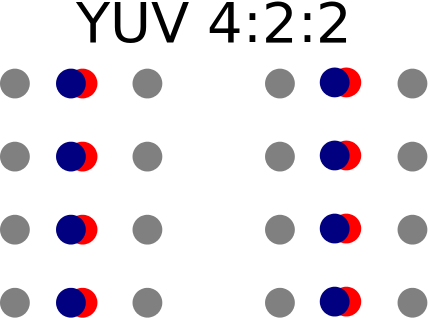
Fig 1 : For two consecutive Y values (black dots) , there is only one set of color components Cr/Cb
The data transmission of the YUV data is realized by sending the U component for even pixels and V component for odd pixels. For a line the transmission looks like the following.

So, two consecutive Y pixels share the same U/V components (Y0 and Y1 share U0V0).
One advantage of such data transmission is that if your processing only needs the grayscale image, you can drop the U/V components to create a grayscale image instead of computing Y from the corresponding RGB value. In the following we will only base our computations on this YUV color space.
cnn.com
Interfacing With the Camera
Now that we understand the camera bus, we can now capture image information to make it available for processing on the FPGA. As you noticed, the camera pixel bus is synchronous (there is a clock signal) so we could just take the bus data as it is output by the camera and directly use the camera clock to synchronize our computation. This approach is often used when the pixel clock is at a high frequency (for HD images or high frame-rate cameras), but it requires that each operation on a pixel can only take one clock cycle. This means that if the operation takes more than one clock cycle you’ll have to build a processing pipeline the size of your computation.
Digression on Pipelining
Pipelining is used when you want to apply more than one operation to a given set of data and still be able to process that data set in one clock-cycle. This technique is often used at the instruction level in processors and GPUs to increase efficiency. Lets take a quick example that computes the following formula.
Y = A*X + B (with A and B being constant)
To compute the value of Y for a given value of X you just have to do one multiplication followed by one addition.
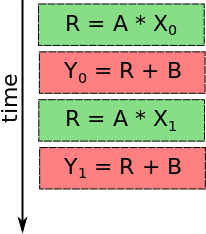
In a fully sequential way, the processing takes two steps. Each time you get a new X value you must apply the two operations to get Y result. This means that a new value of X data can enter the processing pipeline every two steps, otherwise the processing loses data.
If you want to apply the same processing but still be able to compute a new value of Y at each step, and thus process a new X incoming data at each step, you’ll need to apply pipelining, which means that you will process multiple values of X at the same time. A pipeline for this operation would be:

So after the first step there is no Y value computed, but on second step Y0 is ready, on the third step Y1 is ready, on the fourth step Y2 is ready and so on. This pipeline has a latency of two (it takes two cycles between data entering the pipeline and the corresponding result going out of the pipeline). Pipelining is very efficient for maximizing the total throughput or processing frequency of data. Though, pipelining consumes more resources, as you need to have more than one operation being executed at a given time. For example if your computation takes say 9 operations, you’ll need to have a 9 stage pipeline (9 steps latency) and must have 9 computing resources working at the same time.
The decision for where to apply pipelining is based upon the maximum task processing frequency required for the hardware, resources available for the hardware and in some cases power consumption of the hardware, i.e. the higher the processing clock , the more power loss in current leakage.
Back to our application
Using the LOGI Boards, we consider that we have a rather small FPGA (9K Logic elements and few DSP blocks) with limited resources and that the frequency of performance is not an issue where the VGA image at 30FPS produces a data stream with ~12Mpixels per second. So, we won’t use the pixel-clock as the clock source for our system, but rather use a 100Mhz system clock for processing and will consider that at most we have 4 clock cycles to process each pixel (max of ~24Mhz pixel clock => VGA@60Fps).
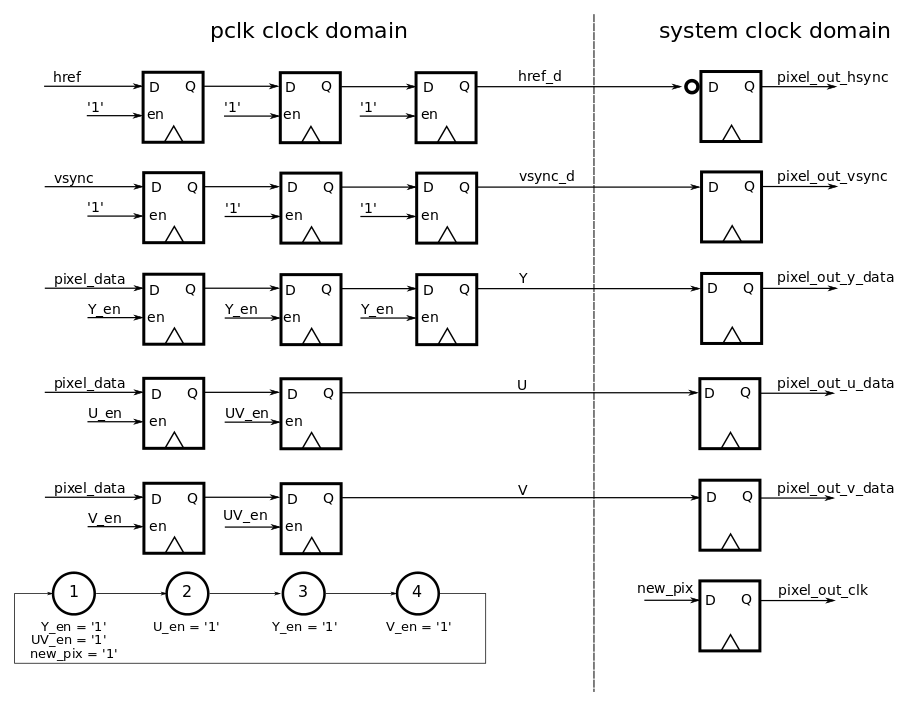
Here is the component view of the camera interface for the YUV pixel data bus:

The component generates a pixel bus with YUV and synchronization signals from the multiplexed bus of the camera. The new bus is synchronous to the system clock. This means that to grab pixels from the camera and be able to process them, we need to work with two different clock domains, the camera clock domain and the system clock domain. The two clock domains are asynchronous to each other, i.e.there is no guaranteed phase relation between the two clocks. To make the two asynchronous domains work together, and to ensure that no metastable conditions occur (see link below for explanation and further information on this topic), we need to perform clock domain crossing to make sure that the data coming out of the camera can be processed with the system clock. In that case the simplest and cheapest way to perform clock domain crossing, is to use a multi-flop synchronizer circuit.
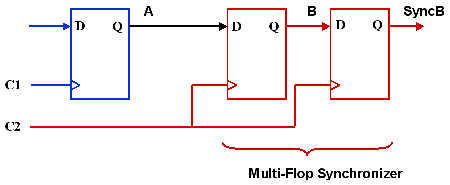
This synchronizer circuit is made of an input flip-flop synchronized in the input clock domain and a set of two flip-flop synchronized in the output clock domain.
What is a Flip-flop ?
A flip-flop is basically the component at the base of most digital circuit whose behavior evolves over time. A D flip-flop has an input named D, and output named Q and a time-base called the clock. In terms of time, the input at the flip-flop is the future and the output of the flip-flop is the present. Each time there is a clock tick (when a rising edge appears on the clock input) , the time evolves a single step and the present becomes the future (Q takes the value of D at the clock-tick).

If you think of a basic operation such as counting, it basically involves adding one to the present value to compute the future value (and so on). A counter circuit can be described as a D-latch (of N bits depending on the maximum count you want to support) whose input is the output value plus one. Additionally a flip-flop can have an enable input, that enable the copy of D on Q only when its asserted and a reset input, that set Q to an initial value.
If you want to know more about flip-flop you can read :
http://www.allaboutcircuits.com/vol_4/chpt_10/5.html
Back to our synchronizer problem, the case of the camera and the FPGA having two different clocks and thus two different clock domains. The problem is that the time evolution of two independents clock domains is not synched by the same time-base. For a D-flip-flop to work the future (D input) must be stable for a given amount of time before the clock-tick (setup time) and while the clock is high (hold time). But when the input of a flip-flop is not in the same clock domain, it’s not possible to guarantee theses timing conditions. The synchronizer circuit is required to minimize the risk of registering an unstable future input into the target clock-domain (more on that inhttp://www.altera.com/literature/wp/wp-01082-quartus-ii-metastability.pdf).
The camera stream
The data from the camera multiplexes the luminance (Y) and chroma (colors UV) pixel data. Thus, we need to de-multiplex the Y and the UV components of data and generate a pixel bus where each rising-edge of the new pixel-clock sends the luminance and chroma associated to the pixel. This principle is displayed in following diagram.
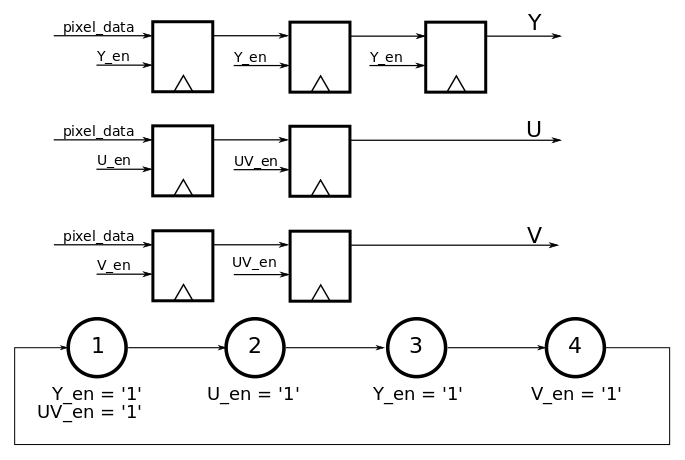
This architecture is synchronized to the pixel_clock generated by the camera. This means that for each new clock cycle, data is latched the D flip-flops. The data signals that are latched are decided based upon which enable signals are activated. The enable signals are generated by the state-machine that evolves at each clock cycle. In practice this specific state machine is implemented as a counter, as there are no transition conditions (transition happen on each clock rising edge).
Finite State Machine
A finite state machine (FSM) is a model for a sequential process. In this model, the behavior is captured by a set of states (the numbered circles in the previous figure) that are connected through transitions (the arrows between states). These transitions can be conditioned, meaning that the transition between two states can only occur if the associated condition holds true. Each state is associated to a set of actions that are maintained as long as the state is active. A state machine is built from three components : state memory, state evolution, and action. The state memory holds current state of the state machine, while the state evolution compute the future state based on the system inputs and present state. The actions are computed from current state (Moore state machine) and system inputs (Mealy state machine). If you want to know more on state-machine you can read :
http://en.wikipedia.org/wiki/Finite-state_machine
http://www.altera.com/support/examples/vhdl/vhd-state-machine.html
http://www.uio.no/studier/emner/matnat/fys/FYS4220/h13/lectures/5-statemachines.pdf
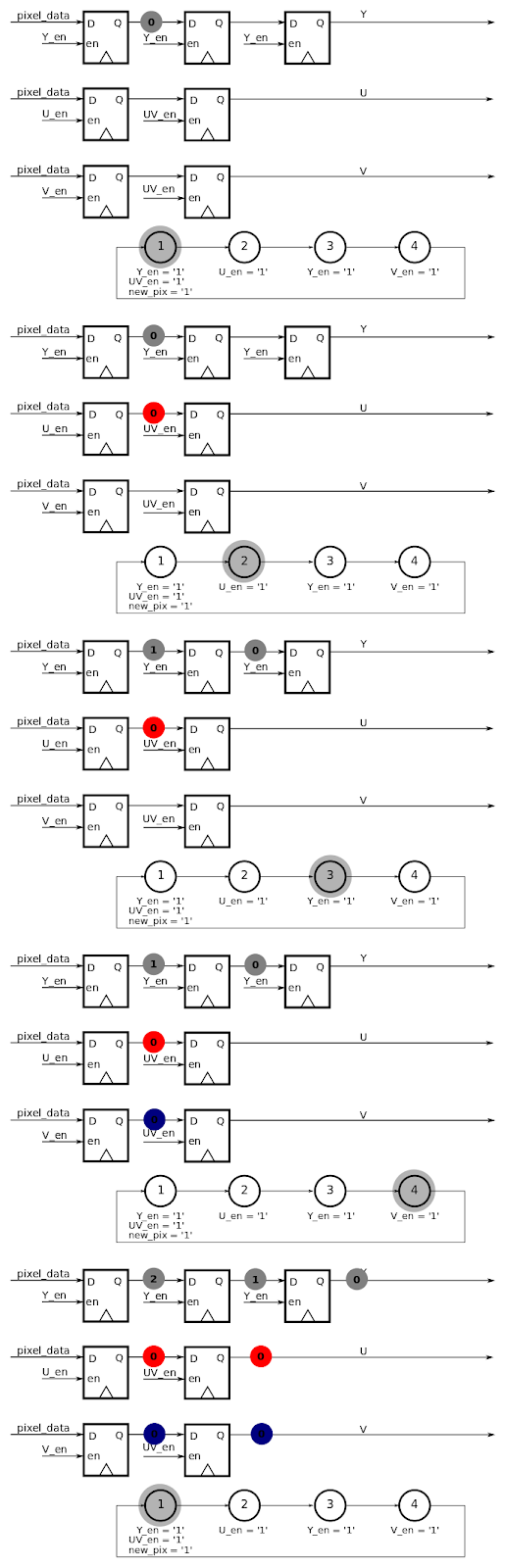
Fig 3 : Sequence of the camera interface to understand how U/V data are stored to be used for two consecutive Y values
The outputs of this architecture are fed into a single flip-flop synchronizer (one DFF in each clock domain) and the pixel_out_hsync (inverted signal of href), pixel_out_vsync, pixel_out_clock are generated to be synchronous to the system clock.
The output of the camera interface can then be fed in the appropriate filter. In future development we will stick to this bus format nomenclature (pixel_<out/in>_hsync, pixel_<out/in>_vsync, pixel_<out/in>_clock, pixel_<out/in>_data ) so that all of the filters we design can be chained together easily.
Now that we have an interface to the camera, we can start designing the first image filter. The design of a 2D convolution operator will be detailed in part 2 of this article. But for now we have left you some useful links which can help better understand the design concepts that are being used in this project.
Getting Deeper Into the Article Topics
How the eye extracts color information using cones and rods:
http://en.wikipedia.org/wiki/Photoreceptor_cell
More on clock domain crossing and metastability:
http://www.altera.com/literature/wp/wp-01082-quartus-ii-metastability.pdf
More on YUV color space :
http://en.wikipedia.org/wiki/YUV
The OV7670 datasheet :
http://www.voti.nl/docs/OV7670.pdf
More on rolling-shutter vs global shutter:
http://www.red.com/learn/red-101/global-rolling-shutter
Download the latest LOGI projects repository and start having a look at the project and associated HDL.
Vision-related components for FPGA (yuv_camera_camera_interface.vh for correponding code)
The Problem
Typical obstacle detection on low cost mobile indoor robots are usually performed using a variety of sensors, namely sonar and infrared sensors. These sensors provide poor information that is only able to detect the presence of a reflective surface in the proximity of the sensor and the distance from the surface. While in most cases it’s enough to navigate a robot on a crowded floor, it does not help the robot for other tasks and adds more sensors to the robot. This does not allow to deviate from the long used paradigm one task = one sensor.
A camera provides rich information that can be processed to extract a large collection of heterogeneous information for the robot to make decisions. A single image allows, for example, to detect colored items, obstacles, people, etc.
One problem that remains with using a camera is that it can be tricked by specific patterns (optical illusions, or homogeneous scene), or changes in the environment (lighting change for example).
Active vision adds a light (visible or infrared) projector to the system that adds information to the scene, which helps the image processing algorithm. An Example of this is Microsoft's first version of the Kinect which used an infrared projector to allow 3D reconstruction from any scene. Recovering depth information (3D or pseudo 3D) in vision can be performed through three distinct methods:
-
Stereo-vision: Two cameras can be used to recover depth information from a scene (like our eyes and brain do)
-
Active vision: Projecting known information onto a scene allows to extract depth (just like the kinect or most 3D scanners)
-
Structure From Motion: SFM works in mono or a multi-vision. The 3D information is recovered by capturing images from different points of view with respect to time (Simultaneous Localization And Mapping SLAM does that). Our brain also uses SFM. For example, close an eye and you are still able to construct 3D information by moving your head/body or by subtle movements of the eye.
With 3D information about a given scene, it’s fairly easy to detect obstacles, assuming the definition that an obstacle is an object that sticks out of the ground plane (simple definition).
All these techniques are quite hard to implement in software and harder to implement in hardware (FPGA) and require a lot of computing power to be performed in real-time.
A simpler method to detect an obstacle is to reconstruct 1D information (distance to an object) from the camera using a 1D projector, namely a dot projector or a line projector, such as a laser line seen in figure 1.. It’s even easier to simply raise an alarm about the presence of an obstacle for a given orientation or defined threshold in the robot frame (radar style information). 2D information (depth and X position of object) can be extracted by making multiple 1D measurements.
The Method
The following example pictures the basic principle of a 2D method of object detection using a 1D line..

Fig 1 :This picture shows the camera view of a laser line projected on the ground. The image of the laser line appears shifted when hitting an obstacle.
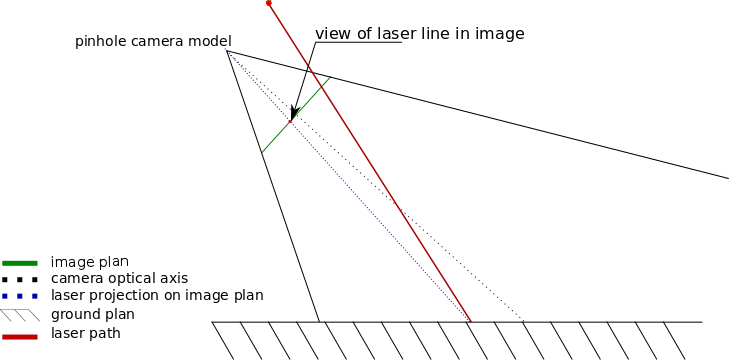
Fig 2: In the normal case the image of the laser on the ground appear at a given position in the image.

Fig 3: When the laser hit an obstacle its image appear shifted compared to the case without obstacle
The 2D object detection method involves
-
Projecting information onto the scene
-
Detecting the projected information in the scene image
Using a laser line, each column in the captured camera image frame can be used to make an independent depth measurement (1D measurement in each column). This allows to achieve a 2D measurement by getting an obstacle detection for each column of the image.
Detecting The Line
The laser line in the image has two distinguishable properties:
-
It’s red
-
It’s straight
A naive approach to detecting the laser line would be to detect red in the image and try to identify segments of the line based on this information. The main problem with the red laser in that case is that because of the sensitivity of the camera, highly saturated red can appear white in the image. Another problem is that because of optical distortion of the camera lens, a line will transform into a curve in the image (film a straight line with a wide angle lens like on the GoPro and you clearly see the effect).
One interesting property of the red laser line, is that because of the intensity, it will generate a high gradient (change of light intensity) along the image column.

Fig 4: Grayscale view of the laser line

Fig 5 : Image of gradient in the vertical direction
This means that one way to discriminate the laser in the image is to compute the gradient along the image column, detect the gradient maximum along the column and assume it’s the line. This gives the position of the laser in each column of the image.
On a fully calibrated system (camera intrinsics , extrinsics, distortion parameters, stereo-calibration of laser/camera, etc) the metric distance to the object could be extracted. In our case we assume that the robot navigates on flat ground and that as a consequence, the laser image should always appear at the same position for each column. If the position moves slightly, it means that there is an object protruding from the ground plane. This allows the algorithm to determine that there is an obstacle on the robot’s path.
The Build
The robot base is purchased from dfrobot (http://www.dfrobot.com/index.php?route=product/product&product_id=367&search=miniq&description=true) and the motors are driven by an Arduino motor shield (L298 based). The FPGA is in charge of generating the PWM signals for each motor (also in charge of PID control in a future evolution), interface of the camera, gradient computation, column max computation. The position of the max for each column is made available to the BeagleBone Black that reads it using the python library and computes the motor PWM duty cycle to be written in the PWM controller register.
A 7.2v NiCd battery powers the motors and a 5V regulator powers the BeagleBone Black.
The LOGI-Cam is equipped with a laser line using the high-current output available on the LOGI-Cam board. A 3D printed mount allows to set the orientation of the laser line, and a wide angle lens was mounted on the camera to allow detection of object at a closer range.

Fig 6: The camera fitted with the laser mount and a wide angle lense

Fig 7: Laser connected to high current output of logi-cam.
Note the bead of hot glue to avoid putting stress on the solder joints.
Also note the wire that shorts the optional resistor slot to get max current (the laser module already has a built-in resistor)

Fig 8: The assembled bot with a angled cardboard support to point assembly toward ground
The FPGA
The design for the FPGA is available on our github account https://github.com/fpga-logi/logi-projects/tree/master/logi-laser-bot . This design is composed of a pixel processing pipeline that grabs a YUV frame from the camera, extract the Y component, applies a gaussian filter (blurring to limit image noise effect on gradient), applies a sobel filter, computes maximum value of vertical gradient for each column and stores the maximum position in memory. The memory can be accessed from the wishbone bus. The wishbone bus also connects an i2c_master to configure the camera, a PWM controller to generate PWM for the motors, a GPIO block to control the direction of the motor and the laser state (on/off) and a FIFO to grab images from the sensor for debugging purposes.
Results
A video showing the robot running obstacle and cliff detection can be viewed at http://youtu.be/SGZVa55p9Lo .
The system works fairly well but is very sensitive to lighting conditions and acceleration of the robot. One side effect of the chosen method is that the sensor also works as cliff detection ! When there is a cliff, the laser disappears from the camera field of view and a random gradient is detected as max. This gradient has little chance to be where the laser is detected and as a consequence an obstacle is reported making the robot stop. The resulting robot system is also pretty heavy for the motor size and inertia causes the robot to stop with a bit of delay. The video was shot with the algorithm running at 15Fps (now runs fine at 30Fps) and with debugging through a terminal window running over wifi, which causes the control loop to not run as fast as possible.
Future Improvements
The current method is quite sensitive to the lighting of the scene, the reflectivity of the scene, the color of the scene (detecting the red laser line on a red floor won't work well). To improve the reliability we can work in the spectral domain with less interference with the projector. Using an infrared laser line and using a bandpass filter on the camera we can isolate the system from natural perturbations. One problem with this method is that the images from the camera cannot be used for other tasks.
Another problem can arise with neon lighting that creates variation in lighting (subtle for the eye, not for a camera). More over, the camera being a rolling shutter (all image lines are not captured at the same time but in sequence) the change in lighting creates change in luminosity along the image line, which in turn creates a perfectly Y-axis oriented gradient that interferes with the laser created gradient. The camera has 50Hz rejection but it’s not working as expected.
Another improvement could be to extend to the 3D detection scenario using a 2D projector (like on the Kinect). This would require to detect dots (using the Harris or Fast detector algorithms) and a 3D point cloud could be computed by the processor.
For those who don’t own a LOGI Board
The technique described in this article is generic and can also be performed in software using OpenCV for the vision algorithms. In comparison the power of using an FPGA is that it allows to perform the vision operations at a much faster pace and lower latency (time difference between an event occur in the scene and the detection) than what a CPU can perform. The FPGA can also simultaneously generate the real-time signals for the motors (PWM). With a Raspberry Pi + Pi-camera or Beaglebone-Black + USB camera you can expect to reach ~10fps in QVGA and an unpredictable latency.
Getting Deeper Into the Theory
Pinhole camera model : http://en.wikipedia.org/wiki/Pinhole_camera_model
Understand the camera model used in most algorithm.
Multiple View Geometry Richard Hartley and Andrew Zisserman,Cambridge University Press, March 2004
Know everything about camera calibration, and geometry involved in image formation
Hardware/Software Co-design with the LOGI Boards
Introduction
In a previous blog post ValentF(x) gave an explanation of what FPGAs (field programmable gate arrays) are and how they are a very valuable resource when designing electronics systems. The article went on to describe the major differences in the way FPGAs operate from CPU/MCU technology. Finally, it was highlighted that FPGAs, especially when used in conjunction with CPU technology, are a powerful tool with both having their own respective strong points in how they process data.
This blog article focuses on how a user should begin to look at using an FPGA in conjunction with a CPU using a co-processing system. The user will better understand how the system is designed to handle processing multiple tasks, scheduling, mapping of the processing tasks and the intercommunication between the LOGI FPGA boards and the host CPU or MCU.
This article will use examples from the LOGI Face project, which is an open source animatronics robot project as the basis for discussing the co-processing methodologies. We will be using real examples from the LOGI projects. Additionally we will refer the user to the LOGI Face Lite project which is a more basic version of LOGI Face that the user can fully replicated with 3D printable parts and off-the-shelf components. The LOGI Face Lite wiki page contains instructions to build and run the algorithms in the project.
What is Hardware/Software Co-design ?
Co-design consists of designing an electronics system as a mixture of software and hardware components. Software components usually run on processors such as a CPU, DSP or GPU, where hardware components run on an FPGA or a dedicated ASIC (application specific integrated circuit). This kind of design method is used to take advantage of the inherent parallelism between the tasks of the application and ease of re-use between applications.
Steps for Designing a Hardware/Software Co-processing System
-
Partition the application into the hardware and software components
-
Map the software components to the CPU resources
-
Map the needed custom hardware components to the FPGA resources
-
Schedule the software components
-
Manage the communications between the software and hardware components
These steps can either be performed by co-design tools, or by hand, based on the knowledge of the designer. In the following we will describe how the LOGI Pi can be used to perform such a co-design in run real-time control oriented applications or high performance applications with the Raspberry Pi.
Communication between the LOGI Pi and Raspberry Pi
A critical requirement of a co-design system is the method of communication between the FPGA and CPU processing units of the platform. The processing units in this case are the LOGI FPGA and the Raspberry Pi. The LOGI projects use the wishbone bus to ensure fast, reliable and expandable communication between the hardware and software components. The Raspberry Pi does not provide a wishbone bus on its expansion, so it was required to take advantage of the SPI port and to design a hardware “wrapper” component in the FPGA that transforms the SPI serial bus into a 16 bit wishbone master component. The use of this bus allows users to take advantage of the extensive repository of open-source HDL components hosted on open-cores.org and other shared HDL locations.
To handle the communication on the SPI bus each transaction is composed of the following information.
1) set slave select low
2) send a 16 bit command word with bits 15 to 2 being the address of the access, bit 1 to indicate burst mode (1) , and bit 0 to indicate read (1) or write (0) (see figure).
3) send/receive 16 bit words to/from the address set in the first transaction. If burst mode is set, the address will be increased on each subsequent access until the chip select line is set to high (end of transaction).
4) set slave select high
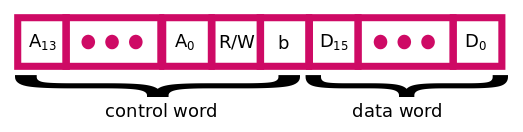
Such transactions allow users to take advantage of the integrated SPI controller of the Raspberry Pi which uses a 4096 byte fifo. This access format permits the following useful bandwidth to be reached (the 2 bit of synchro is transfer overhead on the SPI bus):
-
For a single 16 bit access :(16 bit data)/(2 bit synchro + 16 bit command + 16 bit data) => 47% of the theoretical bandwidth.
-
For a 4094 byte access : ( 2047 * (16 bit data))/(2 bit synchro + 16 bit command + 2047 * (16 bit data) 99.7% of the theoretical bandwidth.
This means that for most control based applications (writing/reading registers), we get half of the theoretical bandwidth, but for data based applications, such as writing and reading to buffers or memory, the performance is 99% of the theoretical bandwidth. It could be argued that getting rid of the wishbone interface and replacing it with an application specific data communication protocol (formatted packet of data) on the SPI bus could give the maximum bandwidth, but this would break the generic approach that is proposed here. The communication is abstracted using a dedicated C API that provides memory read and write functions. ValentF(x) also provides a library of hardware components (VHDL) that the user can integrate into designs (servo controller, pwm controller, fifo controller, pid controller …).
Communication between the LOGI Bone and BeagleBone
The BeagleBone exposes an external memory bus (called GPMC General on its P8 and P9 expansion connectors. This memory bus, provides 16-bit multiplexed address/data, 3 chip select, read, write, clock, address latch, high-byte/low-byte signals.The bus behavior is configured through the device-tree on the linux system as a synchronous bus with 50Mhz clock. This bus is theoretically capable of achieving 80MB/s but current settings limit the bus speed to a maximum of 20MB/s read, 27MB/s write. Higher speeds (50MB/s) can be achieved by enabling burst access (requires to re-compile the kernel) but this breaks the support for some of the IPs (mainly wishbone_fifo). Even higher speeds were measured by switching the bus to asynchronous mode and disabling DMA, but the data transfers would then increase the CPU load quite a lot.
On the FPGA side, ValentF(x) provides a wishbone wrapper that transforms this bus protocol into a wishbone master compatible with the LOGI drivers. On the Linux system side a kernel module is loaded and is in charge of triggering DMA transfers for each user request. The driver exposes a LOGI Bone_mem char device in the “/dev” directory that can be accessed through open/read/write/close functions in C or directly using dd from the command line.
This communication is also abstracted using a dedicated C API that provides memory read/write functions. This C API standardizes function accesses for the LOGI Bone and LOGI Pi thus enabling code for the LOGI Bone to be ported to the LOGI Pi with no modification.
Abstracting the communication layer using Python
Because the Raspberry Pi platform is targeted toward education, it was decided to offer the option to abstract the communication over the SPI bus using a Python library that provides easy access function calls to the LOGI Pi and LOGI Bone platforms. The communication package also comes with a Hardware Abstraction Library (HAL) that provides Python support for most of the hardware modules of the LOGI hardware library. LOGI HAL, which is part of the LOGI Stack, gives easy access to the wishbone hardware modules by providing direct read and write access commands to the modules. The HAL drivers will be extended as the module base grows.
A Basic Example of Hardware/Software Co-design with LOGI Face
LOGI Face is a demonstration based on the LOGI Pi platform that acts as a telepresence animatronic device. The LOGI Face demo includes software and hardware functionality using the Raspberry Pi and the LOGI Pi FPGA in a co-design architecture.
LOGI Face Software
The software consists of a VOIP (voice over internet protocol) client, text to voice synthesizer library and LOGI Tools which consist of C SPI drivers and Python language wrappers that give easy and direct communication to the wishbone devices on the FPGA. Using a VOIP client allows communication to and from LOGI Face from any internet connected VOIP clients, giving access to anyone on the internet access to sending commands and data to LOGI face which are communicated to the FPGA to control the hardware components. The software parses the commands and data and tagged subsets of data are then synthesized to speech using the espeak text to voice library. Users can also use the linphone VOIP client to bi-directionally communicate with voice through LOGI Face. The remote voice is broadcasted and heard on installed speaker in LOGI Face and the local user can then speak back to the remote user using the installed microphone in LOGI Face.
LOGI Face Hardware
The FPGA hardware side implementation consists of a SPI to wishbone wrapper, wishbone hardware modules including servos(mouth and eyebrows), RGB LEDs (hair color), 8x8 LED matrix (eyes) and SPI ADC drivers. The wishbone wrapper acts as glue logic that converts the SPI data to the wishbone protocol. The servos are used to emulate emotion by controlling the mouth which smiles or frowns and the eyebrows are likewise used to show emotions. A diagram depicting the tasks for the application can be seen in the following diagram.

LOGI Face Tasks
The LOGI Face applications tasks are partitioned on the LOGI Pi platform with software components running on the Raspberry Pi and hardware components on the LOGI Pi. The choice of software components was made to take advantage of existing software libraries including the espeak text to speech engine and linphone SIP client. The hardware components are time critical tasks including the wishbone wrapper, servo drivers, led matrix controller, SPI ADC controller and PWM controller.
Further work on this co-processing system could include optimizing CPU performance by moving parts of the espeak TTS (text to speech) engine and other software tasks to hardware in the FPGA. Moving software to the FPGA is a good example that showcases the flexibility and power of using an FPGA with an CPU.
A diagram with the final co-processing tasks of the LOGI Face application can be see in the following diagram.

LOGI Face Lite
LOGI Face Lite is a simplified version of the above mentioned LOGI Face project. The LOGI Fave Lite project was created to allow direct access to the main hardware components on LOGI Face. LOGI Face Lite is intended to allow users to quickly build and replicate the basic software and hardware co-processing functions including servo, SPI ADC, PWM RGB LED and 8x8 Matrix LEDs. Each component has an HDL hardware implementation on the FPGA and function API call access from the Raspberry Pi. We hope that this give users a feel for how they might go about designing a project using the Raspberry Pi or BeagleBone and the LOGI FPGA boards.
Note that the lite version has removed the VOIP Lin client and text to speech functionality to give users a more direct interface to the hardware components using a simple python script. We hope this that will make it easier to understand and begin working with the components and that when the user is ready will move to the full LOGI Face project with all of the features.

Diagram of wiring and functions
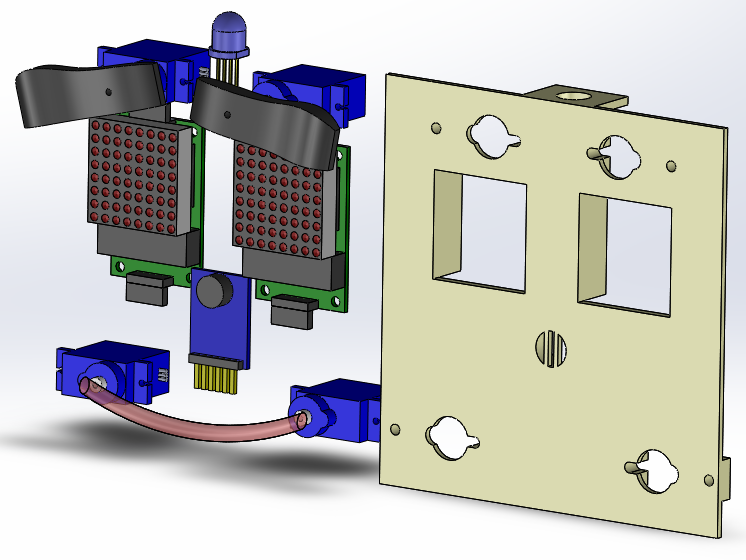
3D model of frame and components

Assembled LOGI Face Lite
FPGA Control
-
2x Servos to control the eyebrows - mad , happy, angry, surprised, etc.
-
2x Servos to control mouth - smile, frown, etc
-
1x RGB LEDs which control the hair color, correspond to mood, sounds, etc
-
2 x 8x8 LED matrices which display animated eyes - blink, look up/down or side to side, etc
-
SPI microphone connected ADC to collect ambient sounds which are used to dynamically add responses to LOGI Face
Software Control
Each of the FPGA controllers is accessible to send and receive data from on the Raspberry Pi. A basic example Python program is supplied which shows how to directly access the FPGA hardware components from the Raspberry Pi.
Build the HDL using the Skeleton Editor
As an exercise the users can use LOGI Skeleton Editor to generate the LOGI Face Lite hardware project, which can then be synthesized and loaded into the FPGA. A Json file can be downloaded from the wiki can can then be imported into the Skeleton Editor, which will then configure the HDL project the user. The user can then use the generated HDL from Skeleton Editor to synthesize and generate a bitstream from Xilinx ISE. Alternatively we supply a pre-built bitsream to configure the FPGA.
Re-create the Project
We encourage users to go to the LOGI Face Lite ValentF(x) wiki page for a walk through on how to build the mechanical assembly with a 3D printable frame, parts list for required parts and instructions to configure the Skeleton project, build the hardware and finally run the software.
http://valentfx.com/wiki/index.php?title=LOGI_Face_Lite_-_Project
You can also jump to any of these resources the project
Conclusion
The LOGI Pi and LOGI Bone were designed to develop co-designed applications in a low cost tightly coupled FPGA/processor package. On the Raspberry Pi or BeagleBone the ARM processor has plenty of computing power while the Spartan 6 LX9 FPGA provides enough logic for many types of applications that would not otherwise be available with a standalone processor.
A FPGA and processor platform allows users to progressively migrate pieces of an application to hardware to gain performance while an FPGA only platform can require a lot of work to get simple tasks that processors are very good at. Using languages such as Python on the Raspberry Pi or BeagleBone enables users to quickly connect to a variety of library or web services and the FPGA can act as a proxy to sensors and actuators, taking care of all low-level real-time signal generation and processing. The LOGI Face project can easily be augmented with functions such as broadcasting the weather or reading tweets, emails or text messages by using the many available libraries of Python. The hardware architecture can be extended to provide more actuators or perform more advanced processing on the sound input such as FFT, knock detection and other interesting applications.
We hope to hear from you about what kind of projects you would like to see and or how we might improve our current projects.
References
http://espeak.sourceforge.net/
http://www.linphone.org/technical-corner/liblinphone/overview
https://github.com/jpiat/hard-cv
https://github.com/fpga-logi/logi-projects
https://github.com/fpga-logi/logi-hard
http://valentfx.com/wiki/index.php?title=LOGI_Face_Lite_-_Project
END OF BLOG _____________________________________________________

Images used on the wiki - DO NOT REMOVE…...



Alternatives to VHDL/Verilog for Hardware Design
Hardware description languages (HDLs) are a category of programming languages that target digital hardware design. These languages provides special features to design sequential logic( the system evolve over time represented by a clock) or combinational logic (the system output is a direct function of its input). While these language have proved to be efficient to design hardware, they often lack the tool support (editors are far behind what you can get to edit C/java/etc) and the syntax can be hard to master. More-over, these language can generate sub-optimal, faulty hardware which can be very difficult to debug.
Over the past-year some alternative languages have arisen to address the main issues of the more popular HDLs (VHDL/Verilog). These new languages can be classified into two categories as follows.
Categories of Hardware description Languages (HDLs)
-
HLS (High Level Synthesis) : HLS tools, try to take an existing programming language as an input and generate the corresponding HDL (hardware description language).. Some of these tools are quite popular in the EDA industry such as CatapultC from Mentor Graphics, Matlab HDL coder, but are very expensive. Xilinx recently integrated the support of SystemC and C in their Vivado toolchain but it only supports high-end FPGA.
-
Alternative syntax : Some tools propose an alternative syntax to VHDL or Verilog. The alternative syntax approach keeps the control of the generated hardware, but gives the advantage of an easier to master syntax and sometimes of ease of debugging.
While the HLS seems attractive. there is a good chance it will generate sub-optimal hardware if the designer does not write the “software” with hardware in mind. The approach is a bit magical as you can take existing C/Matlab software and generate hardware in a few clicks.
HLS is very practical to reduce time to first prototype (especially with Matlab) and for people with little (or no) HDL knowledge to produce a functional hardware design. However, HLS tools are not good for the users who want to learn digital design and the good HLS tools are usually very expensive (a CatapultC license can cost more than 100k$ [link], and Matlab HDL coder starts at 10k$ [link]).
Over the past year some open-source, free to use alternatives to HDL have emerged. These tools do not pretend to create hardware from behavioral description, but propose to smoothen the learning curve for digital logic design by relying on easier to master syntax and feature rich tools.
In the following we will review two of these alternatives languages (myHDL, PSHDL). To test the languages, we will use them to design and debug a simple PWM module. We chose these two languages based on their distinct properties and community adoption but other tools such as MiGen (python based syntax) which will not be covered here, but use the same kind of design flow.
Category 1 - myHDL [http://www.myhdl.org/]
myHDL uses python to design and test hardware components. A hardware component is designed as a python function whose arguments are the inputs and outputs of the component. The component can then describe sub-functions and designate them as combinational or sequential logic using a decorator (some text prefixed by the @ symbol that defines properties for a function/method). Once the design is complete, it can be exported to HDL (VHDL or Verilog) using a small python snippet. The design can also be tested/simulated in the python environment and generate waveform traces.
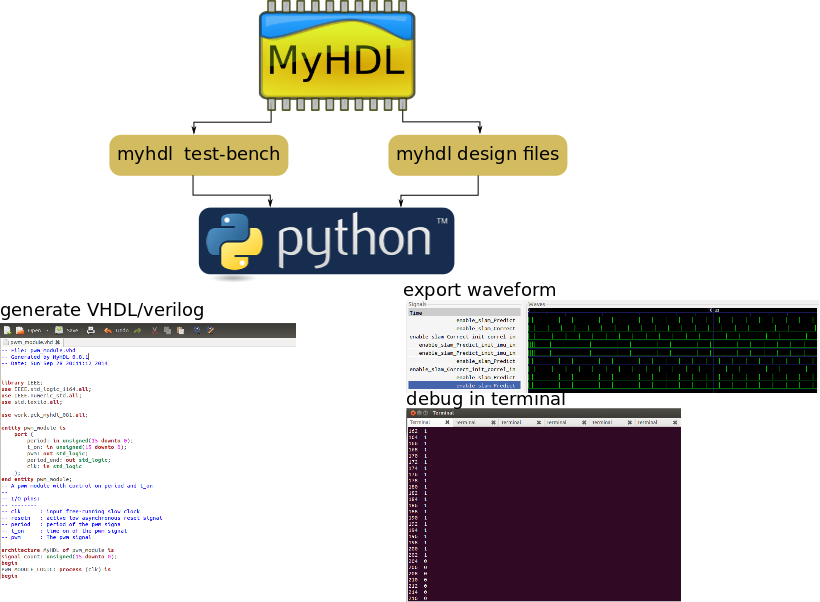
Installation of myHDL
Installing myHDL is straightforward and can be done with a single line on a Linux system(not tested with windows).
sudo pip install myhdl
Design of the PWM module in myHDL
The pwm component is pretty straightforward. It has two inputs period and t_on that designate respectively the period of the pwm signal and the number of cycles that the pwm edges are triggered on. The module has two outputs: pwm_out that is the pwm signal and period_end that is asserted at the end of a period and de-asserted otherwise. Here is the corresponding myHDL code.
from myhdl import *
def pwm_module(period, t_on, pwm, period_end, clk):
count = Signal(intbv(0)[16:])
@always(clk.posedge)
def logic():
if count == period:
count.next = 0
period_end.next = 1
else:
count.next = count + 1
period_end.next = 0
if count > t_on:
pwm.next = 0
else:
pwm.next = 1
return logic
The module is evaluated/simulated using the following test-bench.
def TestBench():
clk = Signal(bool(0))
period = Signal(intbv(200)[16:])
t_on = Signal(intbv(100)[16:])
pwm_out = Signal(bool(0))
period_end = Signal(bool(0))
pwm_inst = pwm_module(period, t_on, pwm_out, period_end, clk)
@always(delay(1))
def tb_clkgen():
clk.next = not clk
@instance
def tb_stim():
period = 200
t_on = 100
yield delay(2)
for ii in xrange(400):
yield clk.negedge
print("%3d %s" % (now(), bin(pwm_out, 1)))
raise StopSimulation
return tb_clkgen, tb_stim, pwm_inst
if __name__ == '__main__':
Simulation(TestBench()).run()
The Corresponding HDL code is generated by changing this line of code:
pwm_inst = pwm_module(period, t_on, pwm_out, period_end, clk)
into this line of code:
pwm_inst = toVHDL(pwm_module, period, t_on, pwm_out, period_end, clk)
and here is the resulting VHDL:
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.numeric_std.all;
use std.textio.all;
use work.pck_myhdl_081.all;
entity pwm_module is
port (
period: in unsigned(15 downto 0);
t_on: in unsigned(15 downto 0);
pwm: out std_logic;
period_end: out std_logic;
clk: in std_logic
);
end entity pwm_module;
architecture MyHDL of pwm_module is
signal count: unsigned(15 downto 0);
begin
PWM_MODULE_LOGIC: process (clk) is
begin
if rising_edge(clk) then
if (count = period) then
count <= to_unsigned(0, 16);
period_end <= '1';
else
count <= (count + 1);
period_end <= '0';
end if;
if (count > t_on) then
pwm <= '0';
else
pwm <= '1';
end if;
end if;
end process PWM_MODULE_LOGIC;
end architecture MyHDL;
myHDL lines to VHDL lines : 20 -> 42 = 0.47
Pro and Cons of using myHDL or similar languages
Pro:
-
Python syntax is clean and forces the user to structure the code appropriately
-
The syntax elements introduced for hardware design are relevant and does not add much syntax (the next attribute is a great idea and reflects the hardware behavior)
-
The quality of the generated code is great !
-
The simulation has a great potential, you can even generate a waveform
-
One can take advantage of the extensive collection of Python packages to create powerful simulations
-
Small designs can fit in one file.
Cons:
-
The use of decorators is not great for readability (and i’am not a decorator fan …)
-
One really needs to understand digital logic and hardware design before starting a myHDL module
-
One really needs to master the basics of Python before getting started
-
Python will raise errors for syntax errors but simulation does raise warning or errors if there is a design error (incomplete if/case clause or other things that a synthesizer would detect)
-
There is no (that i know of) myHDL specific editor or environment that would ease the beginner experience.
Category 2 - The Custom Syntax Approach - PSDHL [http://pshdl.org/]
PSHDL (plain and simple hardware description language) is an HDL language with custom syntax that takes elements inherited from C/SystemC and adds a custom set of keywords and coding elements to represent a hardware module. A module has no arguments but declares some internal variables as “in” or “out”. The nice and clever thing about PSHDL is that only one keyword is used to represent a sequential part of the module. Instead of declaring a computational unit of sequential or combinational logic, a keyword “register” is used to identify the variables/signals that are to be updated in a synchronous process. This is particularly relevant because every HDL design will be translated into LUTs, MUXs, D-latches or registers.
The PSHDL syntax is fairly easy to understand and there is not much syntactical noise. The best thing about PSHDL is that it runs in the web browser! Just like the mBED initiative (for ARM micro-controllers), the pshdl.org website, proposes to create a workspace in which you can edit, compile (to VHDL) and debug your design all on-line. This means, no tools to install (still need to install the ISE/quartus tools to synthesize), OS independent (no problem with running it under Linux/Windows. The community is rather small up until now, but the tool deserves a try!
Creating the PWM module using PSHDL
Below is the PSHDL code for the pwm module:
module de.tuhh.ict.pwmModule {
@clock in bit clk;
in uint<16> period, t_on;
out bit pwm_out, period_end;
register(clock=clk) uint<16> counter;
if(counter > period){
counter = 0;
period_end = 1 ;
}
else{
counter = counter + 1;
period_end = 0;
}
if(counter > t_on){
pwm_out = 0;
}
else{
pwm_out = 1;
}
}
Below is the VHDL code generated by PSHDL
library ieee;
use ieee.std_logic_1164.all;
use ieee.numeric_std.all;
use work.Casts.ALL;
use work.ShiftOps.ALL;
use work.Types.ALL;
entity de_tuhh_ict_pwmModule is
port (
rst : in std_logic;
clk : in std_logic;
period : in unsigned(15 downto 0);
t_on : in unsigned(15 downto 0);
pwm_out : out std_logic;
period_end : out std_logic
);
end;
architecture pshdlGenerated of de_tuhh_ict_pwmModule is
signal counter : unsigned(15 downto 0);
begin
process(counter, period, t_on)
begin
pwm_out <= '0';
period_end <= '0';
if (counter > period) then
period_end <= '1';
else
period_end <= '0';
end if;
if (counter > t_on) then
pwm_out <= '0';
else
pwm_out <= '1';
end if;
end process;
process(clk)
begin
if RISING_EDGE(clk) then
if rst = '1' then
counter <= (others => '0');
else
if (counter > period) then
counter <= (others => '0');
else
counter <= (counter + TO_UNSIGNED(1, 16));
end if;
end if;
end if;
end process;
end;
PSHDL lines to VHDL lines : 21 -> 51 = 0.41
Pro and cons
Pros :
-
Online tool ! No installation and is OS agnostic
-
Easy to use syntax for people who know C/C++
-
Clever use of the “register” keyword to denote sequential assignments
-
Outputs nicely formatted VHDL
-
Generated VHDL interfaces easily with existing VHDL code
Cons:
-
Online tool - some people may complain that its not great for privacy and intellectual property
-
Some syntax elements like the package prefix for a module create lengthy text
-
A “register” can be associated to a clock and reset by passing arguments to it. This is misleading for C/C++ programmers as it creates a type with an argument (and not a template like the other types) which is not valid C/C++ code.
-
Simulation does not seem to be fully functional in the online tool
-
The community is small (but can grow if you give it a try)
Conclusion
These two alternative HDL languages/tools do a great job to ease the process of writing and debugging HDL. They both rely on different principles. myHDL defines combinational/sequential functions while PSHDL defines sequential signals for the sequential behavior. This allows you to pick what works best for you! The main drawback with both of these (tools and other alternatives languages) is that they are not directly supported in the vendor tools (Quartus/ISE) and that they are not recognized as standard hardware design languages in the professional world. This means that you will still have to learn VHDL/Verilog at some point if this is part of your career plan.
There is no indication that FPGA vendors are willing to open the access to their synthesis tools for third parties, so for any VHDL/Verilog alternatives you will still have to install and use their tools to synthesize and create the binary files to configure the FPGA.
One other language that tends to emerge as a standard for hardware (and system) design is SystemC (at least with Xilinx). While myHDL does not rely on any of the SystemC concepts, PSHDL has the advantage of being (to some extend) C/C++ based.
To get more people to use FPGAs there is a need to propose a large diversity of languages/tools. See the diversity of languages available to program microcontrollers. Some years ago you had to use C or assembler to design embedded software, but now you can use C/C++, Arduino (C++ based), javascript, Python and more. We need the same kind of languages competition for HDL as each new language may attract more users and create new uses for FPGAs.
What features do you foresee being needed for a killer hardware description language?
We could not have done it without YOU!
We want to sincerely thank all of those who supported us through our LOGI boards Kickstarter. It was a risk and you chose to give us a chance and it made all the difference. We were able to successfully complete the kickstarter and are ready to continue to support the LOGI boards and create new and interesting FPGA/Processor related products. We feel that your name will be on all of the current and future products based upon your support of us. We can’t thank you enough and hope to pay you back in great products and support!
This page is dedicated to all of the LOGI kickstarter backers and below are the names of those who chose to be listed.
| Roland G. McIntosh | Bruce Bock | Jules V. Jenson | Rickey E. Askew |
| David Archibald | David B | junjiq | Rob Crowther |
| A Alnaqi | Deema A. | Justin Frodsham | Rob See |
| Aaron Shaw | derek jacoby | Justin Hubbard | Robert Amos |
| Adam Sunderland | Derek Molloy | Justin To | Robert Berger - Reliable Embedded Systems |
| Adrian Klink | Don Allison | Karel Koranda | Robert Joscelyne |
| Ahmad Albaqsami | Donald D. Parker | Ken Sheets | Ron Young |
| Ahmad Byagowi | Douglas B. Fletcher | Ken Steffey | Rudy De Volder |
| Alex Brem | Dr. Duane king | Kidged | Ruskigt Anonym |
| Alexandru Cucos | Eduardo Sugai | Lambda Automation | Russ Herrold |
| Almende | Efficient Computer Systems, LLC | Larry G Byars | Ryan Messina |
| Alphonsos Pangas | Eirik S. Mikkelsen | Lyndon Nerenberg | Ryuu Minastas |
| Ameet Gandhare | Eric Dube | M0les | saad C. |
| Andreas | Erlend Hoel | Mahmood Hanif | Samuel Nielson |
| Andrew McLaughlin | Evan Fosmark | Marco Antonio Assfalk de Oliveira | SAULO RUSSO S1GM9 |
| Andrew Troutman | Falk Schilling | Marco Tommasoni | Scott Dolin |
| Andy Fundinger | Foli Ayivoh | Marcus Hunger | Scott Watson |
| Andy Gelme | Frederik S. | Mark Davidson | Shane Ley |
| Andy Gikling | FredF | Mark Lobo | Sietse |
| Anton Shmagin | Gar L Fisher | Mark Philpott | silicium (Антон Малиновский) |
| Ari Kamlani | Garrett Burgwardt | Mark Richardson | Simon |
| Art Teranishi | Geoff Webb | Mark Titley | Simon Kennedy |
| B.Bimmermann | George Bangerter | Markus Fix | Simon Parker |
| Back | Gerald Orban | Martin G. Ryan | Some Guy |
| Bastiaan Topper | Gianduia | Martin Haeberli | Srihari Yamanoor |
| believeintechnology | Guilherme Martins | Martin Steiner | Stefan Brüns |
| Benjamin | Guitian | Marwan Marwan | Stefan Johannesdal |
| Benoît Gilon | Hans-Martin Frey | Mathew Cosgrove | Stephen Corona |
| Bernard Roth | hen918 | Mathew Mills | Stephen Loschiavo |
| Bilbo Baggins | Henner | Matt D | Stephen Olesen |
| Bill "Bubba" Nixon | Howard Logsdon | Matthew Crocker | stephen warren |
| Bill Nace | Huuf | Matthew Downen | Steve Braswell |
| Bill Penner | Israel Garcia | Matthew Henley | Steven K. Knapp |
| Blake Palacio | Ivan Goh Han Siong | Max Z | Steven Knudsen |
| Brian O'Connor | Jacek Krzywicki | Maxime Bedard | Svenne Krap |
| C.M. Stacy | Jack A. Cummings | Merv | Thomas Thaler |
| cd wrestler | Jalil Vaidya | Michael Giambalvo | Tim Wells |
| Chad Furman | James Brett Sloan | Michael Haig | Tom Lasinski |
| Chandra Bajpai | jason ball | Michal Aichinger | Tony Moretti |
| Charles Steinkuehler | Jason Doege | Mike Delaney, P.E. | Trung Tin Ian HUA |
| Cheng Ta Yang | Jdubb | Morgan Hough | Venkat |
| Chih Yuan Lo | jiahao jian | Nathanael Nunes | Vin Gravh |
| Chris Kopp | Jim Meyer | Neil Matthews | Voloshin Evgeniy |
| Chris Nordby | Jim Stephens | Nelson Brown | Watson Huang |
| Claudio Vendrame | Joe Michael | Nicholas Rutzen | Wei-ju Wu |
| Clinton Campbell | Joeri Martens | Norman Jaffe | william george |
| Cody C. Brunson | Johan Elmerfjord | Paolo Conci | William J Caban-Babilonia |
| Conor Wright | John Boudreaux | Paul Augart | William T Argyros |
| Craig "The Coder" Dunn | John Mulder | Paul Wortmann | www.kasuro.com |
| Craig Clark | John W. C. McNabb | Peter Andersen | Xamayon |
| Craig I. Hagan | Jojolamenace | Peter Korcz | Xark |
| Daniel Krusenbaum | Jon G. | Petr Hladký | Osman H. EL-BABA |
| Daniel Rebori-Carretero | Jonathan Edwards | Pieterjan Maes | |
| Daniel Roberts | Jonathan Rippy | PR Taylor | |
| Daniel Stensnes | Jörn Hoffmann | Pranav Maddula | |
| Dave Auld (http://www.dave-auld.net) | Joshua James | psq | |
| Dave Hylands | Joshua Warren | Rich Vuduc | |
| Dave Wick | Juan | Rick Adorjan | |
| David A Katz | Juergen Finke |
Mike and Jonathan of ValentF(x) hope to create useful blog posts that serve the purpose of helping electronics generalists to better understand FPGA technology. We hope to create some elementary blogs which walk through basics and then move to working through fun and interesting applications that use common CPU platforms including the Raspberry Pi and BeagleBone while working in conjunction with FPGAs. We hope that this blog serves as a starting point of working from the basics of FPGAs and moving to more complex topics and applications that users are most interested in. Please give us feedback on what you would like to see in the fpga group at http://www.element14.com/community/groups/fpga-group
Here are some thoughts of topics and discussion that might work well for future blog posts, but we hope you ultimately drive where we end up going with this, so let us know!
Potential Future ValentF(x) FPGA Blog posts
-
How do FPGAs fit within the wide world of electronics around us
-
Understanding the complementary nature of FPGAs technology to widely used CPU technology
-
Learn how to implement the LOGI Stack of software and drivers to make implementing FPGAs easier for the end user
-
Walk through examples and applications implementing FPGA technology in order for users to become comfortable delving into their own projects
-
Implement and walk through LOGI projects such as machine vision, autonomous vehicle control, robotics and more.
-
Implement and walk through user requested projects.
-
FPGAs and CPUs - Apples and Oranges
Field programmable gate array (FPGA) technology is highly contrasting to the more well known and widely used CPU technology. There a key differences between the two which make them very complimentary for use with each other. At the low level, FPGAs are made of transistor configurations which implement logic gates that combine to make combinational logic or flip flops that can then combine to make up register transfer logic (RTL) and the hierarchy and abstractions keeps going up from there. These combinations and abstractions are put together to create CPUs, custom hardware processing modules that are found in application specific integrated circuits (ASICs) and/or the combination of the multitude of digital integrated circuits found on the market today. With the difference between ASICs and FPGAs being that the FPGA can be reprogrammed or configured an unlimited number of times with user defined applications where the ASIC has a single fixed configuration of functionality.
FPGAs are similar to CPUs in that they are able to process data. If a CPU needs to handle tasks A, B and C, it would typically start with task A and move through task B and C in a linear fashion to finish the tasks. As the CPU is given new tasks, the tasks are added sequentially and are processed until they are all finished. The CPU may become loaded with too many tasks that take a large number of instructions to complete, slowing down the processing which may make the CPU unviable for the specific application and tasks at hand. This often happens, for example, in real-time systems where the timing of tasks are critical . The solution would be to either remove some of the tasks or use a faster processor if the users chose to continue using a sole CPU.
If an FPGA had the same tasks, A,B,C, the tasks could be constructed so that each task was being processed at the same time or in parallel within the FPGA fabric. Any new tasks are also processed in parallel so that no additional time is required for the additional processing. Tasks can continue to be added as long as there is enough logic within the FPGA. The parallel tasks can vary from simplistic digital gate logic to more complex configuration that make up high speed digital processing such as image processing and digital signal processing, all being added in parallel without affecting any of the original A,B,C, processes that are running concurrently on the FPGA.
FPGAs are Logic Fabric - FPGAs are like a Chameleon
FPGAs are widely used in the electronics industry because of their unrivaled ability to be fully reconfigured to support any number of contrasting applications while not requiring any modification to the PCB hardware or design. FPGAs are commonly referred to as “logic fabric”. This term implies that the logic fabric can be modified, cut, pieced and applied in many different configurations to create customized applications that otherwise might require the design and fabrication of an ASIC (very expensive) or by using a mixture of different discrete logic and/or processing solutions. Many times FPGAs are used in designs knowing that the design requirements will change and the FPGAs would need to be updated to meet the changes without modifying the existing board hardware. The only change that would be required would be for new HDL code to be written and loaded into the FPGA, assuming the inputs and outputs have not changed. In this way, FPGAs are like a chameleon, taking on new colors or disguises to adapt to changing environments.
These examples are not intended to imply that FPGAs are superior to CPUs, but to show that the two technologies operate very differently from each other. Both technologies are very good at doing what they do in their respective processing paradigms. The FPGAs ability to have new functionality added to it without affecting the performance of existing functionality makes it great for applications that require flexibility and expandability. When used together, the qualities of the CPUs and FPGAs complement each other and deliver outstanding results.
Introducing the LOGi FPGA Boards
The LOGI Boards were designed with key attributes in mind
-
Overcome the sharp learning curve of working with FPGAs by enabling multiple levels of entry to using FPGAs
-
Enable users to easily create CPU/FPGA systems using open source drivers, software and HDL for communication between the CPU and FPGA
-
Create an educational pathway for beginners to understand and proficiently work with FPGAs
-
Maximum plug and play interfacing with existing hardware using Pmod and Arduino modules
-
Enable access to fully functional high performance open source projects
An FPGA Experience For Beginners or Advanced Users
The LOGI Apps
The LOGI Apps give FPGA beginners an easy way begin working working with advanced applications very quickly with no need to write any code. The LOGi Apps can run developed highly functional applications by simply typing “sudo make_demo.sh” to run a shell script from the linux command line. The user only needs to plug in any needed hardware modules and then run the script, which builds the source code, configures any drivers and loads the FPGA with an appropriate bitfile to the FPGA. The user then has a fully functional and running application that can be used as is, modified to suit special needs or simply used a reference to understand the underlying source code and drivers. Current LOGI Apps include machine vision, bitcoin mining algorithms, virtual components, logic analyzer, wishbone interfacing and more, See the LOGI Apps wiki page for documentation and a guide to using the LOGI Apps.
LOGI Skeleton Editor
For users who want to create their own customized HDL without needing to write a line of code, meet the LOGI Skeleton Editor. Skeleton Editor is a web based graphical HDL composer that can be used to customize and configure projects using graphical components. ValentF(x) has created an array of graphical components that the users can configure graphically within the web based editor to fit their needs. The configured Skeleton project can then be shared, saved or produce the HDL that the user can then synthesize and implement within their LOGI products with support and communication for the CPU platforms. See the LOGI skeleton Editor wiki page for more documentation and a guide to using the graphical editor.
The LOGI Stack
Underlying the LOGI Ecosystem is the LOGI Stack. The LOGI stack consists of software, drivers, firmware and HDL that allows users a seamless interface between the FPGA and the host CPU when using the LOGI development boards. The key to successfully using a mixed CPU and FPGA co-processing system is allowing them to transparently and efficiently read and write data between the CPU and FPGA. The LOGI Stack allows users to quickly create their own CPU/FPGA applications by giving the user easy read and write access, software and drivers to efficiently communicate between the Raspberry PI or BeagleBone and the LOGI FPGA Boards. See the LOGI Stack wiki page for more information. Below is an image of the layers contained within the LOGI Stack.

Educational Pathway for Beginners to learn and become Proficient with using FPGAs
The most important aspect of working with FPGAs is understanding digital logic, HDL, FPGAs and the concepts of making them work together. In order to create a successful FPGA system from custom HDL requires that the user have a base knowledge of these components. ValentF(x) has created an Educational pathway to working with FPGAs with the LOGI EDU Package.
The LOGi-EDU package is an expansion board board for the LOGi Pi FPGA board. The LOGi-EDU serves as an educational pathway to allow FPGA beginners to easily learn and implement an HDL design within FPGAs. The educational pathway walks beginners through the basic steps of FPGA and HDL design by using examples from the book “FPGA Prototyping By Verilog Examples” or “FPGA Prototyping By VHDL Examples”. The examples can be run by using the add-on EDU expansion module that supports the book examples and applications. Using these examples allows the user to quickly get up to speed with the basics of FPGA design and allows the user to migrate to designing and working on and designing greater complexity FPGA applications.
User FPGA Accessibility - Conclusion
No matter your experience level, there are fun applications to delve into that use the wide array of available electronics available on the market today. Let the LOGI Boards be your gateway into exploring the latest technologies and in creating fun, high performance, easy to use applications.
LOGI Projects - High Performance Open Source Projects
The LOGi Boards were designed to allow implementation of many high performance applications in a straightforward manner. Many popular applications are best served by the processing capabilities of an FPGA, including SDR (Software defined Radio), quad-copter control, computer vision, and bitcoin mining, robotics and more. Applications have been created for the LOGI Boards that implement machine vision, bitcoin mining, autonomous vehicle robotic controller using GPS, 9-axis IMU, WIFI, and machine vision to run blob detection and color detection algorithms. These applications are representative of a few of the applications that can be developed by using off-the-shelf components and integrating high performance CPU and FPGA technology.
Maximum Interfacing Compatibility with Existing Hardware Modules
The LOGI Boards seek to allow as much plug-and-play expansion to existing available hardware as possible by using widely available and low-cost, off-the-shelf hardware. Pmod and Arduino Shields were chosen to be used as standard interface on the LOGI Boards, based on their wide market usage, availability, and cost. There are currently multiple hundreds of Pmod and Arduino Shields available for purchase. Additionally, high bandwidth LVDS interconnects implementing impedance controlled LVDS lines can be interfaced. By using LVDS, such applications as HDMI, SDR, LVDS camera interfaces, and other high bandwidth applications can easily be developed on the LOGi Boards.
Conclusion
ValentF(x) hopes that by bringing together popular CPU platforms with FPGAs, giving users the LOGI Ecosystem of drivers, software and widely available hardware modules will allow for new and innovative applications to be developed by electronics enthusiasts and professionals alike. The LOGI Team looks forward to continuing to create new and in demand CPU/FPGA projects and applications that users can learn from and use to create their own applications.
For more information about the LOGI Boards visit element14 LOGI page or drop by and open a discussion regarding your FPGA thoughts and interests on the element14 FPGA group.
http://element14.com/logi
http://www.element14.com/community/groups/fpga-group

As you are likely aware there is a new version of the Raspberry Pi available, the B+ version. There have been questions as to whether the current LOGI-Pi R1 is compatible with this new version. The answer is Yes, but to ensure not shorts occur, you will need to put down a piece of kapton (preferable) or any type of tape to isolate some of the arduino pin from the RPi new USB connector.
The new Raspberry Pi B+ design mechanically shifted things around a bit and changed the locations of all mounting holes. Thus, the LOGI-Pi mounting holes are not aligned with the Raspberry Pi mounting holes, but the Raspberry Pi header and LOGI-Pi connector create plenty of friction to hold the boards pretty securely together. The user could optionally add some doublesized tape to the top of the new USB connectors to more securely mate the LOGI-Pi.
Below are images of the LOGI-Pi and Raspberry Pi B+ installed and running. We have updated the latest logi-image to support the B+. You can download the image from the LOGI-Pi Quickstart guide here. If you would like to discuss any B+ related topics, please drop by the forum and drop us a line.
We have created an new logi-image with all needed logi-tools based upon the latest raspbian image. You can download the image here.
Note that we will be updating the current LOGI design to support the new mounting holes of the B+ and the changes will be applied to newly manufactured LOGI-Pi boards.
Cheers!
Add tape to the lower USB connector as shown. Installed LOGI-Pi on Raspberry Pi B+

LOGI-Pi Rpi Bplus Side LOGI-Pi Rpi Bplus Side Running LOGI Camera app with Raspberry Pi B+

