The Problem
Typical obstacle detection on low cost mobile indoor robots are usually performed using a variety of sensors, namely sonar and infrared sensors. These sensors provide poor information that is only able to detect the presence of a reflective surface in the proximity of the sensor and the distance from the surface. While in most cases it’s enough to navigate a robot on a crowded floor, it does not help the robot for other tasks and adds more sensors to the robot. This does not allow to deviate from the long used paradigm one task = one sensor.
A camera provides rich information that can be processed to extract a large collection of heterogeneous information for the robot to make decisions. A single image allows, for example, to detect colored items, obstacles, people, etc.
One problem that remains with using a camera is that it can be tricked by specific patterns (optical illusions, or homogeneous scene), or changes in the environment (lighting change for example).
Active vision adds a light (visible or infrared) projector to the system that adds information to the scene, which helps the image processing algorithm. An Example of this is Microsoft's first version of the Kinect which used an infrared projector to allow 3D reconstruction from any scene. Recovering depth information (3D or pseudo 3D) in vision can be performed through three distinct methods:
-
Stereo-vision: Two cameras can be used to recover depth information from a scene (like our eyes and brain do)
-
Active vision: Projecting known information onto a scene allows to extract depth (just like the kinect or most 3D scanners)
-
Structure From Motion: SFM works in mono or a multi-vision. The 3D information is recovered by capturing images from different points of view with respect to time (Simultaneous Localization And Mapping SLAM does that). Our brain also uses SFM. For example, close an eye and you are still able to construct 3D information by moving your head/body or by subtle movements of the eye.
With 3D information about a given scene, it’s fairly easy to detect obstacles, assuming the definition that an obstacle is an object that sticks out of the ground plane (simple definition).
All these techniques are quite hard to implement in software and harder to implement in hardware (FPGA) and require a lot of computing power to be performed in real-time.
A simpler method to detect an obstacle is to reconstruct 1D information (distance to an object) from the camera using a 1D projector, namely a dot projector or a line projector, such as a laser line seen in figure 1.. It’s even easier to simply raise an alarm about the presence of an obstacle for a given orientation or defined threshold in the robot frame (radar style information). 2D information (depth and X position of object) can be extracted by making multiple 1D measurements.
The Method
The following example pictures the basic principle of a 2D method of object detection using a 1D line..

Fig 1 :This picture shows the camera view of a laser line projected on the ground. The image of the laser line appears shifted when hitting an obstacle.
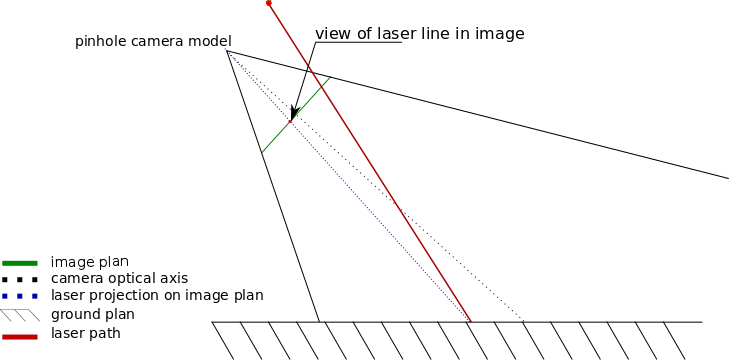
Fig 2: In the normal case the image of the laser on the ground appear at a given position in the image.

Fig 3: When the laser hit an obstacle its image appear shifted compared to the case without obstacle
The 2D object detection method involves
-
Projecting information onto the scene
-
Detecting the projected information in the scene image
Using a laser line, each column in the captured camera image frame can be used to make an independent depth measurement (1D measurement in each column). This allows to achieve a 2D measurement by getting an obstacle detection for each column of the image.
Detecting The Line
The laser line in the image has two distinguishable properties:
-
It’s red
-
It’s straight
A naive approach to detecting the laser line would be to detect red in the image and try to identify segments of the line based on this information. The main problem with the red laser in that case is that because of the sensitivity of the camera, highly saturated red can appear white in the image. Another problem is that because of optical distortion of the camera lens, a line will transform into a curve in the image (film a straight line with a wide angle lens like on the GoPro and you clearly see the effect).
One interesting property of the red laser line, is that because of the intensity, it will generate a high gradient (change of light intensity) along the image column.

Fig 4: Grayscale view of the laser line

Fig 5 : Image of gradient in the vertical direction
This means that one way to discriminate the laser in the image is to compute the gradient along the image column, detect the gradient maximum along the column and assume it’s the line. This gives the position of the laser in each column of the image.
On a fully calibrated system (camera intrinsics , extrinsics, distortion parameters, stereo-calibration of laser/camera, etc) the metric distance to the object could be extracted. In our case we assume that the robot navigates on flat ground and that as a consequence, the laser image should always appear at the same position for each column. If the position moves slightly, it means that there is an object protruding from the ground plane. This allows the algorithm to determine that there is an obstacle on the robot’s path.
The Build
The robot base is purchased from dfrobot (http://www.dfrobot.com/index.php?route=product/product&product_id=367&search=miniq&description=true) and the motors are driven by an Arduino motor shield (L298 based). The FPGA is in charge of generating the PWM signals for each motor (also in charge of PID control in a future evolution), interface of the camera, gradient computation, column max computation. The position of the max for each column is made available to the BeagleBone Black that reads it using the python library and computes the motor PWM duty cycle to be written in the PWM controller register.
A 7.2v NiCd battery powers the motors and a 5V regulator powers the BeagleBone Black.
The LOGI-Cam is equipped with a laser line using the high-current output available on the LOGI-Cam board. A 3D printed mount allows to set the orientation of the laser line, and a wide angle lens was mounted on the camera to allow detection of object at a closer range.

Fig 6: The camera fitted with the laser mount and a wide angle lense

Fig 7: Laser connected to high current output of logi-cam.
Note the bead of hot glue to avoid putting stress on the solder joints.
Also note the wire that shorts the optional resistor slot to get max current (the laser module already has a built-in resistor)

Fig 8: The assembled bot with a angled cardboard support to point assembly toward ground
The FPGA
The design for the FPGA is available on our github account https://github.com/fpga-logi/logi-projects/tree/master/logi-laser-bot . This design is composed of a pixel processing pipeline that grabs a YUV frame from the camera, extract the Y component, applies a gaussian filter (blurring to limit image noise effect on gradient), applies a sobel filter, computes maximum value of vertical gradient for each column and stores the maximum position in memory. The memory can be accessed from the wishbone bus. The wishbone bus also connects an i2c_master to configure the camera, a PWM controller to generate PWM for the motors, a GPIO block to control the direction of the motor and the laser state (on/off) and a FIFO to grab images from the sensor for debugging purposes.
Results
A video showing the robot running obstacle and cliff detection can be viewed at http://youtu.be/SGZVa55p9Lo .
The system works fairly well but is very sensitive to lighting conditions and acceleration of the robot. One side effect of the chosen method is that the sensor also works as cliff detection ! When there is a cliff, the laser disappears from the camera field of view and a random gradient is detected as max. This gradient has little chance to be where the laser is detected and as a consequence an obstacle is reported making the robot stop. The resulting robot system is also pretty heavy for the motor size and inertia causes the robot to stop with a bit of delay. The video was shot with the algorithm running at 15Fps (now runs fine at 30Fps) and with debugging through a terminal window running over wifi, which causes the control loop to not run as fast as possible.
Future Improvements
The current method is quite sensitive to the lighting of the scene, the reflectivity of the scene, the color of the scene (detecting the red laser line on a red floor won't work well). To improve the reliability we can work in the spectral domain with less interference with the projector. Using an infrared laser line and using a bandpass filter on the camera we can isolate the system from natural perturbations. One problem with this method is that the images from the camera cannot be used for other tasks.
Another problem can arise with neon lighting that creates variation in lighting (subtle for the eye, not for a camera). More over, the camera being a rolling shutter (all image lines are not captured at the same time but in sequence) the change in lighting creates change in luminosity along the image line, which in turn creates a perfectly Y-axis oriented gradient that interferes with the laser created gradient. The camera has 50Hz rejection but it’s not working as expected.
Another improvement could be to extend to the 3D detection scenario using a 2D projector (like on the Kinect). This would require to detect dots (using the Harris or Fast detector algorithms) and a 3D point cloud could be computed by the processor.
For those who don’t own a LOGI Board
The technique described in this article is generic and can also be performed in software using OpenCV for the vision algorithms. In comparison the power of using an FPGA is that it allows to perform the vision operations at a much faster pace and lower latency (time difference between an event occur in the scene and the detection) than what a CPU can perform. The FPGA can also simultaneously generate the real-time signals for the motors (PWM). With a Raspberry Pi + Pi-camera or Beaglebone-Black + USB camera you can expect to reach ~10fps in QVGA and an unpredictable latency.
Getting Deeper Into the Theory
Pinhole camera model : http://en.wikipedia.org/wiki/Pinhole_camera_model
Understand the camera model used in most algorithm.
Multiple View Geometry Richard Hartley and Andrew Zisserman,Cambridge University Press, March 2004
Know everything about camera calibration, and geometry involved in image formation