
FPGA Camera Data Processing
This is part 1 of a 2 part article which details interfacing a camera to an FPGA, capturing the data and then processing the data using a pipelining technique. One of the many strengths of using an FPGA is the speed and flexibility it gives to processing data in a real-time manner. An interface to a camera is a good example of this case scenario where cameras output very high amounts of data very quickly and generally customized or dedicated hardware is required to process this data.
One specific attribute of an FPGA is that it can be used to implement a given processing task directly at the data-source, in this case: the camera. This means that with a good understanding of the signals generated by the camera we can adapt image filters to directly process the signals generated by the camera instead of processing an image stored in memory like a CPU would do, i.e. real-time processing.
A camera is a pixel streaming device. It converts the photon into binary information for each pixel. Each pixel is a photon integrator that generates an analog signal followed by an analog to digital converter. The camera then transmits on it’s databus the captured information, one pixel at a time, one row after the other. The pixel can be captured in two different ways that directly affect the kind of application the sensor can be used in, including rolling shutter and global shutter sensors.
Rolling Shutter Camera Sensors
Rolling-shutter sensors are widely adopted because they are cheap and can be built for high resolution images. These sensors do not acquire all the pixels at once, but one line after the other. Because all the pixels are not exposed at the same time, it generates artifacts in the image. For examples take a picture of a rotating fan and observe the shape of the fan blades (see image below for comparison). Another noticeable effect can be seen when taking a picture of scene with a halogen or fluorescent light. When using a halogen or fluorescent light all the pixel lines are not exposed with the same amount of light because light intensity varies at 50/60Hz, which is driven by the mains frequency.
Global Shutter Camera Sensors
Global shutter sensor are more expensive and are often used in machine vision. For these sensors all of the pixels are exposed at the same time with a snapshot. The pixels informations is then streamed to the capturing device (FPGA in our case). These sensors are more expensive because they require more dedicated logic to record all the pixels at once (buffering). Moreover, the sensor die is larger (larger silicon surface), because the same surface contains the photon integrators and the buffering logic.

Once captured, the pixel data can be streamed over different interfaces to the host device (FPGA in our case). Examples of typical camera data interfaces are parallel interfaces or CSI/LVDS serial interfaces. The parallel interface is composed of a set of electrical signals (one signal per data bit), and is limited in the distance the data can be transmitted (inches in scale). The serial interface sends the different pixel information one after another using the same data lines, positive and negative differential pair. LVDS (Low Voltage Differential Signaling) carries the serial data at high rates (up to 500Mbps for a camera) and allows transmission for longer distances (up to 3 feet on the LOGI SATA type connector).
The LOGI Cam
The LOGI Cam supports many of the Omnivision camera modules, but is shipped with the OV7670 which is a low cost rolling shutter sensor that exposes a parallel data bus with the following signals.
pclk: the synchronization clock to sample every other signal, this signal is active all the time
href: href indicates that a line is being transmitted
vsync: vsync indicate the start of a new image
pixel_data: the 8-bit data-bus that carry pixel information at each pclk pulse when href is active
sio_c/sio_d: an i2c like interface to configure the sensor

Fig 0: First diagram show how pixel are transmitted in a line. Second part is a zoom out of the transmission, and just show how line are transmitted in an image.
Pixel Data Coded Representations
The parallel data bus is common for low cost sensors and is well suited to stream pixel data. What one will notice is that the pixel data is only 8 bits wide, which leads to the question, how does the camera send a color data without more that 8 bits per pixel on this data bus? The answer is that each component of the pixel is sent one after another in sequence until the complete pixel data has been transmitted. This means that for a QVGA (240 lines of 320 pixels per line) color image, with 2 bytes per pixel, the camera sends 240 lines of 640 values (2 bytes per pixel).
RGB Color Space
One might wonder how the camera can compose each pixel’s color data with only 2 bytes (i.e. does it produce only 2^16 or 65536 different values)? There are two typical ways to represent the pixel colors, RGB (Red Green Blue) and YUV coding. RGB coding will split the 16bits (two bytes) into an RGB value, on the camera this is called RGB 565, which means that 16bits are split into 5 bits for red, 6 bits for green, 5 bits for blue. You will note that there is an extra bit for the green data. This interesting point is guided by our animal nature which programs our eyes to be more sensitive to subtle changes in green, therefore to create the best range of for a color requires us to add an extra green data bit *. With RGB565 there is a total of 65536 colors based upon a total of 16 color bits available per pixel.
YUV Color Space
The second way of coding pixel data is called YUV (or YCrCb), Y stands for luminance (the intensity of light for each pixel), U/Cr is the red component of the image and V/Cb is the blue component of the image. In YUV, instead of down-scaling the number of bits for each YUV component, the approach is to downscale the resolution for the U/V values. Our eyes are more sensitive to luminance than to color due to the fact that the eye has more rod cells responsible for sensing luminance than cone cells that can sense the colors*. There are a number of YUV formats including YUV 4:4:4, YUV 4:2:2, YUV 4:2:0. Each format will produce a full resolution image for the Y component (each pixel has a Y value) and a downscaled resolution for U/V. In the camera the Y component resolution has at native resolution of 320x240 for QVGA and U/V resolution is down-scaled for each line (160x240 for QVGA), that is the YUV 4:2:2 format. See Figure 1 for a depiction of how the image is broken into components of full resolution Y and downscaled resolution of U/V components. Note that all of the bits are being used for each YUV component, but only every other U/V component is used to downscale the total image size.
* For more information on this topic see the links at the end of the page
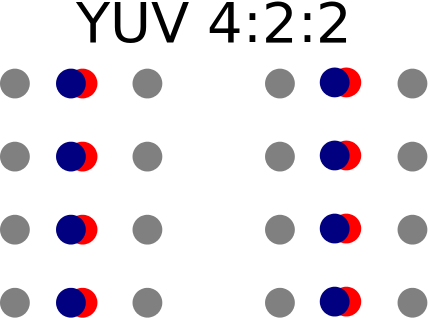
Fig 1 : For two consecutive Y values (black dots) , there is only one set of color components Cr/Cb
The data transmission of the YUV data is realized by sending the U component for even pixels and V component for odd pixels. For a line the transmission looks like the following.

So, two consecutive Y pixels share the same U/V components (Y0 and Y1 share U0V0).
One advantage of such data transmission is that if your processing only needs the grayscale image, you can drop the U/V components to create a grayscale image instead of computing Y from the corresponding RGB value. In the following we will only base our computations on this YUV color space.
cnn.com
Interfacing With the Camera
Now that we understand the camera bus, we can now capture image information to make it available for processing on the FPGA. As you noticed, the camera pixel bus is synchronous (there is a clock signal) so we could just take the bus data as it is output by the camera and directly use the camera clock to synchronize our computation. This approach is often used when the pixel clock is at a high frequency (for HD images or high frame-rate cameras), but it requires that each operation on a pixel can only take one clock cycle. This means that if the operation takes more than one clock cycle you’ll have to build a processing pipeline the size of your computation.
Digression on Pipelining
Pipelining is used when you want to apply more than one operation to a given set of data and still be able to process that data set in one clock-cycle. This technique is often used at the instruction level in processors and GPUs to increase efficiency. Lets take a quick example that computes the following formula.
Y = A*X + B (with A and B being constant)
To compute the value of Y for a given value of X you just have to do one multiplication followed by one addition.
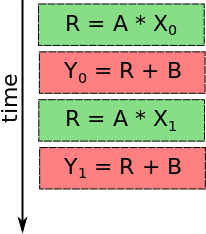
In a fully sequential way, the processing takes two steps. Each time you get a new X value you must apply the two operations to get Y result. This means that a new value of X data can enter the processing pipeline every two steps, otherwise the processing loses data.
If you want to apply the same processing but still be able to compute a new value of Y at each step, and thus process a new X incoming data at each step, you’ll need to apply pipelining, which means that you will process multiple values of X at the same time. A pipeline for this operation would be:

So after the first step there is no Y value computed, but on second step Y0 is ready, on the third step Y1 is ready, on the fourth step Y2 is ready and so on. This pipeline has a latency of two (it takes two cycles between data entering the pipeline and the corresponding result going out of the pipeline). Pipelining is very efficient for maximizing the total throughput or processing frequency of data. Though, pipelining consumes more resources, as you need to have more than one operation being executed at a given time. For example if your computation takes say 9 operations, you’ll need to have a 9 stage pipeline (9 steps latency) and must have 9 computing resources working at the same time.
The decision for where to apply pipelining is based upon the maximum task processing frequency required for the hardware, resources available for the hardware and in some cases power consumption of the hardware, i.e. the higher the processing clock , the more power loss in current leakage.
Back to our application
Using the LOGI Boards, we consider that we have a rather small FPGA (9K Logic elements and few DSP blocks) with limited resources and that the frequency of performance is not an issue where the VGA image at 30FPS produces a data stream with ~12Mpixels per second. So, we won’t use the pixel-clock as the clock source for our system, but rather use a 100Mhz system clock for processing and will consider that at most we have 4 clock cycles to process each pixel (max of ~24Mhz pixel clock => VGA@60Fps).
Here is the component view of the camera interface for the YUV pixel data bus:

The component generates a pixel bus with YUV and synchronization signals from the multiplexed bus of the camera. The new bus is synchronous to the system clock. This means that to grab pixels from the camera and be able to process them, we need to work with two different clock domains, the camera clock domain and the system clock domain. The two clock domains are asynchronous to each other, i.e.there is no guaranteed phase relation between the two clocks. To make the two asynchronous domains work together, and to ensure that no metastable conditions occur (see link below for explanation and further information on this topic), we need to perform clock domain crossing to make sure that the data coming out of the camera can be processed with the system clock. In that case the simplest and cheapest way to perform clock domain crossing, is to use a multi-flop synchronizer circuit.
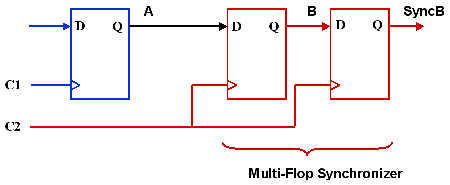
This synchronizer circuit is made of an input flip-flop synchronized in the input clock domain and a set of two flip-flop synchronized in the output clock domain.
What is a Flip-flop ?
A flip-flop is basically the component at the base of most digital circuit whose behavior evolves over time. A D flip-flop has an input named D, and output named Q and a time-base called the clock. In terms of time, the input at the flip-flop is the future and the output of the flip-flop is the present. Each time there is a clock tick (when a rising edge appears on the clock input) , the time evolves a single step and the present becomes the future (Q takes the value of D at the clock-tick).

If you think of a basic operation such as counting, it basically involves adding one to the present value to compute the future value (and so on). A counter circuit can be described as a D-latch (of N bits depending on the maximum count you want to support) whose input is the output value plus one. Additionally a flip-flop can have an enable input, that enable the copy of D on Q only when its asserted and a reset input, that set Q to an initial value.
If you want to know more about flip-flop you can read :
http://www.allaboutcircuits.com/vol_4/chpt_10/5.html
Back to our synchronizer problem, the case of the camera and the FPGA having two different clocks and thus two different clock domains. The problem is that the time evolution of two independents clock domains is not synched by the same time-base. For a D-flip-flop to work the future (D input) must be stable for a given amount of time before the clock-tick (setup time) and while the clock is high (hold time). But when the input of a flip-flop is not in the same clock domain, it’s not possible to guarantee theses timing conditions. The synchronizer circuit is required to minimize the risk of registering an unstable future input into the target clock-domain (more on that inhttp://www.altera.com/literature/wp/wp-01082-quartus-ii-metastability.pdf).
The camera stream
The data from the camera multiplexes the luminance (Y) and chroma (colors UV) pixel data. Thus, we need to de-multiplex the Y and the UV components of data and generate a pixel bus where each rising-edge of the new pixel-clock sends the luminance and chroma associated to the pixel. This principle is displayed in following diagram.
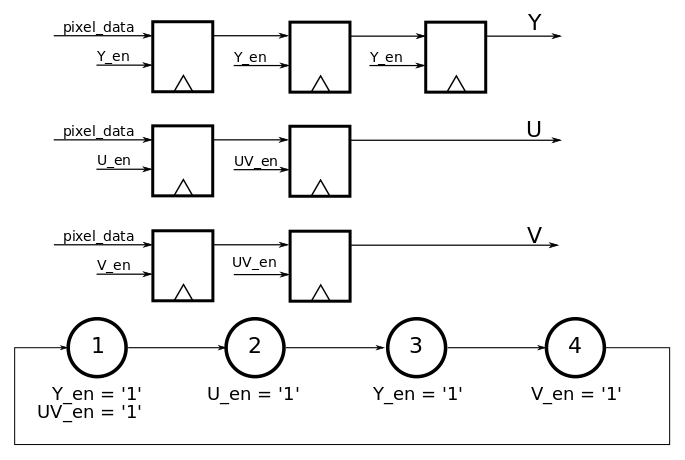
This architecture is synchronized to the pixel_clock generated by the camera. This means that for each new clock cycle, data is latched the D flip-flops. The data signals that are latched are decided based upon which enable signals are activated. The enable signals are generated by the state-machine that evolves at each clock cycle. In practice this specific state machine is implemented as a counter, as there are no transition conditions (transition happen on each clock rising edge).
Finite State Machine
A finite state machine (FSM) is a model for a sequential process. In this model, the behavior is captured by a set of states (the numbered circles in the previous figure) that are connected through transitions (the arrows between states). These transitions can be conditioned, meaning that the transition between two states can only occur if the associated condition holds true. Each state is associated to a set of actions that are maintained as long as the state is active. A state machine is built from three components : state memory, state evolution, and action. The state memory holds current state of the state machine, while the state evolution compute the future state based on the system inputs and present state. The actions are computed from current state (Moore state machine) and system inputs (Mealy state machine). If you want to know more on state-machine you can read :
http://en.wikipedia.org/wiki/Finite-state_machine
http://www.altera.com/support/examples/vhdl/vhd-state-machine.html
http://www.uio.no/studier/emner/matnat/fys/FYS4220/h13/lectures/5-statemachines.pdf
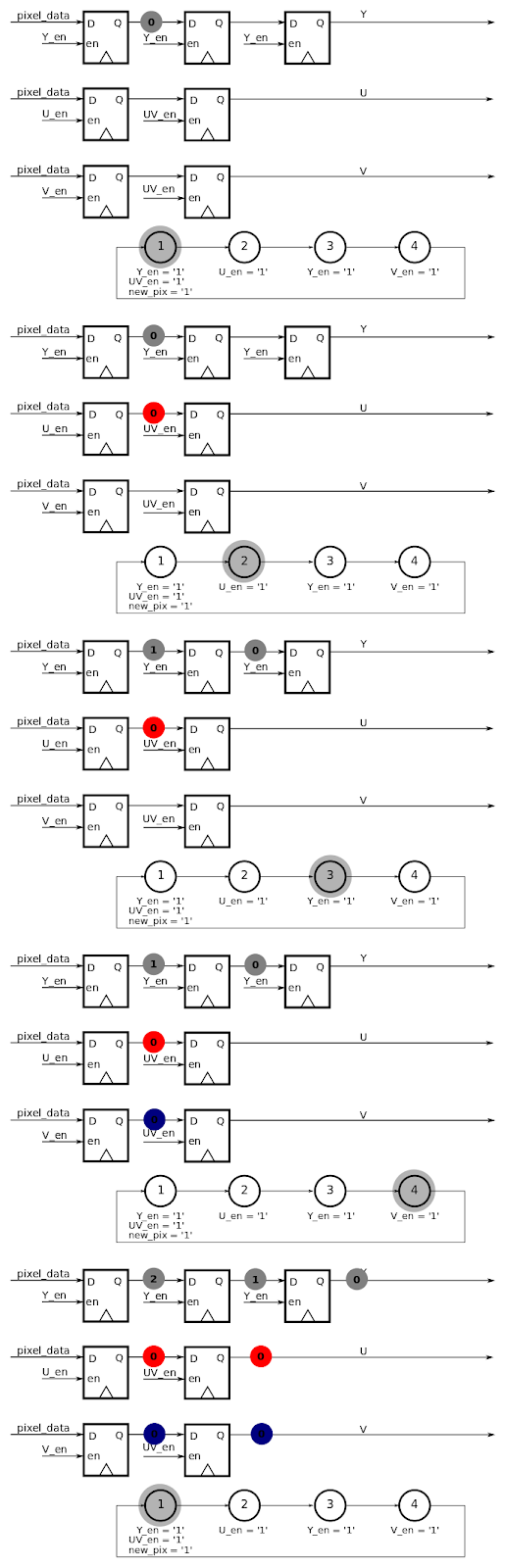
Fig 3 : Sequence of the camera interface to understand how U/V data are stored to be used for two consecutive Y values
The outputs of this architecture are fed into a single flip-flop synchronizer (one DFF in each clock domain) and the pixel_out_hsync (inverted signal of href), pixel_out_vsync, pixel_out_clock are generated to be synchronous to the system clock.
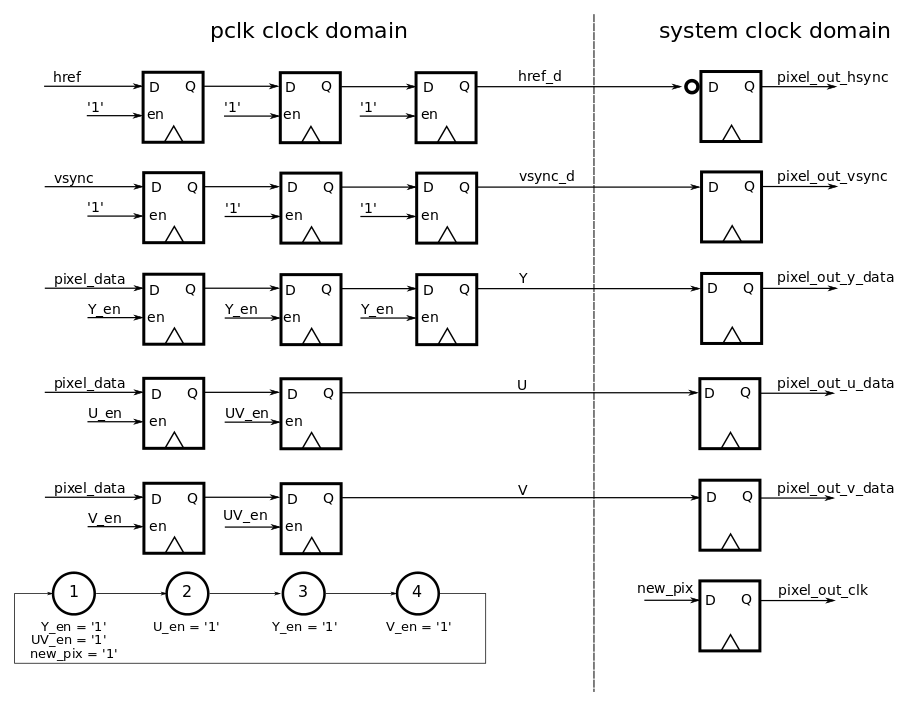
The output of the camera interface can then be fed in the appropriate filter. In future development we will stick to this bus format nomenclature (pixel_<out/in>_hsync, pixel_<out/in>_vsync, pixel_<out/in>_clock, pixel_<out/in>_data ) so that all of the filters we design can be chained together easily.
Now that we have an interface to the camera, we can start designing the first image filter. The design of a 2D convolution operator will be detailed in part 2 of this article. But for now we have left you some useful links which can help better understand the design concepts that are being used in this project.
Getting Deeper Into the Article Topics
How the eye extracts color information using cones and rods:
http://en.wikipedia.org/wiki/Photoreceptor_cell
More on clock domain crossing and metastability:
http://www.altera.com/literature/wp/wp-01082-quartus-ii-metastability.pdf
More on YUV color space :
http://en.wikipedia.org/wiki/YUV
The OV7670 datasheet :
http://www.voti.nl/docs/OV7670.pdf
More on rolling-shutter vs global shutter:
http://www.red.com/learn/red-101/global-rolling-shutter
Download the latest LOGI projects repository and start having a look at the project and associated HDL.
Vision-related components for FPGA (yuv_camera_camera_interface.vh for correponding code)
https://github.com/jpiat/hard-cv